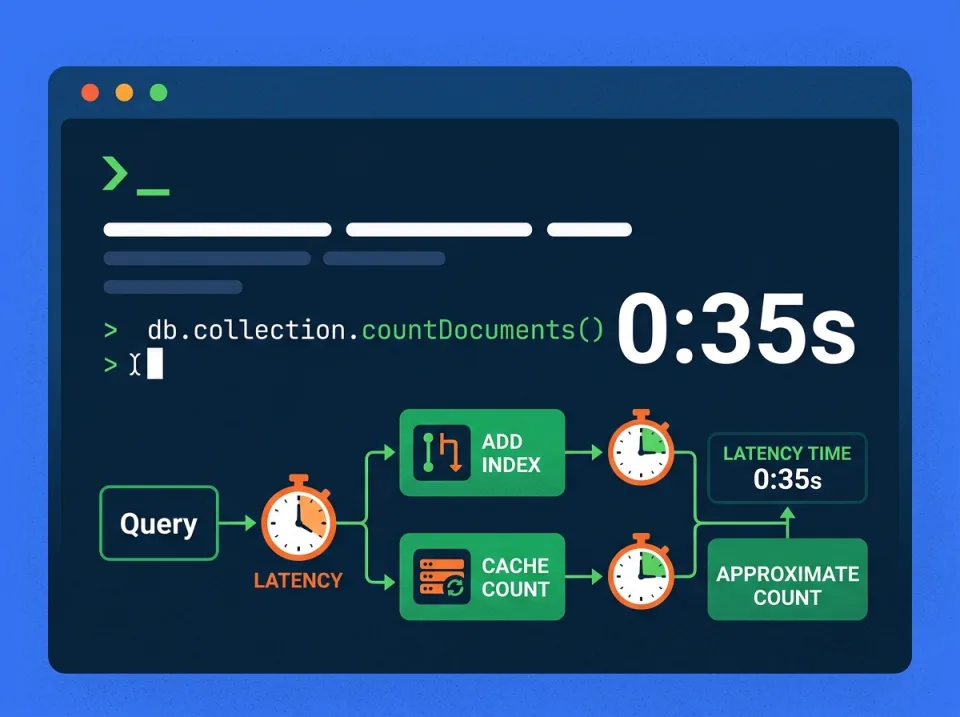

Slow query COUNT(*) pada tabel besar di produksi biasanya muncul saat endpoint list, halaman admin, atau API pencarian selalu menghitung total data pada setiap request. Gejalanya sederhana: query pengambilan data terlihat masih masuk akal, tetapi response tetap lambat karena query COUNT(*) ikut dieksekusi dan memakan waktu paling besar.
Masalah ini jarang selesai hanya dengan “menambah server”. Akar masalahnya biasanya ada pada cara database membaca data: full scan, filter yang tidak didukung index yang tepat, join yang tidak perlu dalam query count, atau kombinasi dengan offset pagination yang membuat beban makin besar. Solusi yang tepat bergantung pada pola query, kebutuhan akurasi total, dan karakter trafik produksi.
Mengapa COUNT(*) bisa lambat pada tabel besar
Secara konsep, COUNT(*) terlihat sederhana karena hanya menghitung jumlah baris. Namun pada tabel besar, database tetap harus menentukan baris mana yang memenuhi kondisi. Jika tidak ada jalur akses yang efisien, database dapat membaca sangat banyak baris atau index entry untuk menghasilkan total yang akurat.
1. Full scan karena filter tidak didukung index
Kasus paling umum adalah query seperti berikut:
SELECT COUNT(*)
FROM orders
WHERE tenant_id = 42
AND status = 'paid'
AND created_at >= '2025-01-01';Jika tabel orders besar dan hanya memiliki index terpisah yang tidak cocok dengan pola WHERE, optimizer bisa memilih rencana yang tetap mahal, bahkan mendekati table scan atau membaca banyak baris dari index lalu melakukan filter tambahan.
Index tunggal pada status saja belum tentu membantu jika kardinalitasnya rendah. Index pada created_at saja juga belum tentu cukup jika tenant menjadi pemisah data utama. Di sinilah composite index sesuai pola query menjadi penting.
2. Join yang tidak perlu dalam query count
Pada banyak aplikasi, query data dan query total dibuat dari builder yang sama. Akibatnya, query count ikut membawa JOIN yang sebenarnya hanya dibutuhkan untuk menampilkan kolom tambahan.
SELECT COUNT(*)
FROM orders o
JOIN customers c ON c.id = o.customer_id
WHERE o.tenant_id = 42
AND o.status = 'paid';Jika tujuan count hanya menghitung order, join ke customers bisa menjadi beban tambahan yang tidak perlu. Join dapat memperbesar jumlah data yang harus diproses, menambah biaya lookup, dan dalam beberapa kasus memaksa query plan yang lebih buruk.
3. Offset pagination memperparah biaya request
Banyak endpoint list menjalankan dua query sekaligus:
- Query data dengan
LIMIT ... OFFSET ... - Query
COUNT(*)untuk total halaman
Offset tinggi sudah mahal karena database harus melewati banyak baris sebelum mengambil halaman yang diminta. Jika di request yang sama Anda juga menghitung total dengan query count mahal, latency akan terasa berlipat. Ini umum terjadi pada halaman admin dengan filter dinamis.
4. COUNT(*) akurat memang tidak gratis
Untuk kebutuhan seperti pagination tradisional yang menampilkan “1 dari 12.384 halaman”, aplikasi sering menuntut angka total yang akurat di setiap request. Pada dataset besar dan filter kompleks, akurasi ini memang memiliki biaya. Trade-off utamanya adalah akurasi vs performa.
Gejala nyata di produksi
Beberapa pola yang sering terlihat:
- Endpoint list terasa lambat hanya ketika filter tertentu aktif.
- Halaman pertama relatif cepat, tetapi halaman berikutnya lambat karena offset membesar.
- Database CPU tinggi walaupun payload response kecil.
- Query data utama tidak terlalu buruk, tetapi query count mendominasi waktu request.
- Lonjakan latency terjadi pada jam sibuk karena count dieksekusi berulang untuk permintaan yang mirip.
Kalau gejalanya seperti ini, fokus investigasi jangan hanya pada query SELECT ... LIMIT .... Sering kali pelaku utamanya justru query COUNT(*).
Cara investigasi slow query COUNT(*)
Gunakan EXPLAIN atau EXPLAIN ANALYZE
Langkah pertama adalah melihat bagaimana database menjalankan query. Jalankan EXPLAIN pada query count yang benar-benar dipakai aplikasi, termasuk filter aslinya.
EXPLAIN
SELECT COUNT(*)
FROM orders
WHERE tenant_id = 42
AND status = 'paid'
AND created_at >= '2025-01-01';Jika database Anda mendukung EXPLAIN ANALYZE, hasilnya lebih berguna karena menunjukkan eksekusi aktual, bukan sekadar rencana estimasi.
EXPLAIN ANALYZE
SELECT COUNT(*)
FROM orders
WHERE tenant_id = 42
AND status = 'paid'
AND created_at >= '2025-01-01';Yang perlu diperhatikan:
- Apakah query melakukan sequential scan atau membaca sangat banyak row?
- Apakah index yang dipakai sesuai dengan kolom filter utama?
- Apakah jumlah row hasil estimasi jauh berbeda dari row aktual?
- Apakah ada join, sort, atau step lain yang sebenarnya tidak perlu untuk count?
Jika query count memakai query builder yang kompleks, ambil SQL final yang benar-benar dieksekusi aplikasi. Menganalisis query yang “disederhanakan” sering menyesatkan.
Aktifkan dan baca slow query log
Slow query log membantu menemukan query count yang sebenarnya paling sering merusak latency. Ini penting karena masalah produksi jarang datang dari satu query ideal, melainkan dari query yang dieksekusi berulang dalam volume tinggi.
Perhatikan:
- Frekuensi query count yang sama atau mirip
- Nilai filter yang dominan
- Durasi query pada kondisi beban normal dan puncak
- Apakah count muncul dari endpoint tertentu saja, misalnya admin list atau export preview
Korelasikan dengan metrik latency aplikasi
Jangan berhenti di database. Lihat juga metrik aplikasi:
- Latency per endpoint
- Persentil seperti p95 atau p99
- Jumlah query per request
- Durasi query count vs query data
- Pool koneksi database yang penuh karena query lama
Sering kali perbaikan terbaik bukan membuat satu query lebih cepat, tetapi mengurangi frekuensi query count secara keseluruhan.
Strategi perbaikan yang paling efektif
1. Buat composite index sesuai pola WHERE
Jika query count selalu memfilter dengan pola yang sama, buat index yang mengikuti pola akses tersebut. Contoh:
SELECT COUNT(*)
FROM orders
WHERE tenant_id = 42
AND status = 'paid'
AND created_at >= '2025-01-01';Index yang lebih relevan biasanya berupa gabungan kolom filter, misalnya:
CREATE INDEX idx_orders_tenant_status_created_at
ON orders (tenant_id, status, created_at);Mengapa ini bekerja? Karena database dapat menelusuri bagian index yang jauh lebih sempit daripada membaca tabel besar secara luas. Jika tenant_id sangat selektif dan hampir semua query selalu menyertakannya, meletakkannya di depan index sering masuk akal.
Namun, urutan kolom index tidak boleh ditebak sembarangan. Pertimbangkan:
- Kolom yang hampir selalu ada di
WHERE - Selektivitas data
- Operasi perbandingan, misalnya equality vs range
- Apakah query lain juga bisa memanfaatkan index yang sama
Kesalahan umum: membuat banyak index tunggal lalu berharap optimizer akan selalu menggabungkannya secara efisien. Dalam banyak kasus, satu composite index yang tepat lebih efektif daripada beberapa index yang terpisah.
2. Pertimbangkan covering index bila relevan
Untuk query count murni, database kadang cukup membaca index tanpa harus kembali ke tabel utama, tergantung mesin database dan rencana eksekusinya. Ini bisa mengurangi I/O. Pada query list, covering index lebih terasa manfaatnya jika semua kolom yang dibutuhkan query tersedia di index.
Namun jangan memaksakan covering index besar untuk semua kasus. Index yang terlalu lebar:
- Memakan storage lebih besar
- Memperlambat
INSERT/UPDATE - Meningkatkan biaya maintenance index
Gunakan jika query yang sama benar-benar kritis dan volumenya tinggi.
3. Pisahkan query total dari query data
Jangan gunakan query builder yang sama persis untuk data dan count jika itu membuat query total ikut membawa JOIN, ORDER BY, atau kolom yang tidak relevan.
Contoh yang lebih sehat:
-- Query data
SELECT o.id, o.order_number, o.status, o.created_at
FROM orders o
WHERE o.tenant_id = 42
AND o.status = 'paid'
ORDER BY o.created_at DESC
LIMIT 50 OFFSET 0;
-- Query total yang disederhanakan
SELECT COUNT(*)
FROM orders o
WHERE o.tenant_id = 42
AND o.status = 'paid';Jika filter harus melibatkan relasi, pastikan join itu memang diperlukan untuk menentukan himpunan baris. Jika join hanya untuk menampilkan nama customer atau atribut dekoratif lain, keluarkan dari query count.
4. Cache hasil count untuk filter yang sering dipakai
Jika halaman admin atau dashboard sering meminta total yang sama dalam rentang waktu singkat, cache adalah strategi yang sangat efektif. Misalnya cache per kombinasi filter tertentu dengan TTL pendek.
Pola sederhananya:
- Bentuk key cache dari parameter filter yang stabil
- Ambil count dari cache jika ada
- Jika tidak ada, jalankan query count lalu simpan hasilnya beberapa detik atau menit
Contoh pseudocode:
cache_key = "orders:count:tenant=42:status=paid"
count = cache.get(cache_key)
if count is null:
count = db.query("SELECT COUNT(*) FROM orders WHERE tenant_id = ? AND status = ?", [42, "paid"])
cache.set(cache_key, count, ttl=60)
return countTrade-off-nya jelas: data bisa sedikit usang selama TTL berlaku. Untuk halaman admin, pencarian, atau dashboard, selisih kecil sering bisa diterima. Untuk kebutuhan audit atau billing, biasanya tidak.
5. Gunakan approximate count untuk dashboard
Tidak semua tampilan membutuhkan angka total yang presisi sampai baris terakhir. Dashboard operasional sering cukup dengan angka perkiraan, selama pengguna memahami sifatnya.
Pendekatan approximate count bisa berupa:
- Menggunakan statistik internal database bila sesuai kebutuhan
- Menyimpan counter teragregasi di tabel terpisah
- Memperbarui angka total secara periodik lewat job background
Contohnya, alih-alih menghitung langsung dari tabel transaksi besar di setiap request, aplikasi menyimpan ringkasan harian atau total per status di tabel summary.
SELECT total_paid_orders
FROM order_summary
WHERE tenant_id = 42;Ini jauh lebih ringan, tetapi Anda harus menerima bahwa datanya mungkin tertinggal beberapa detik atau menit, tergantung mekanisme sinkronisasinya.
6. Evaluasi penggunaan offset pagination
Jika endpoint sangat sering diakses dan jumlah data besar, pertimbangkan cursor pagination atau keyset pagination. Dengan pendekatan ini, database tidak perlu melewati offset besar untuk mengambil halaman berikutnya.
Contoh sederhana:
SELECT id, order_number, status, created_at
FROM orders
WHERE tenant_id = 42
AND status = 'paid'
AND created_at < '2025-04-10 10:00:00'
ORDER BY created_at DESC
LIMIT 50;Cursor pagination tidak otomatis menghilangkan kebutuhan count, tetapi sering membuat Anda bisa menghapus total halaman dari UX. Banyak API modern cukup menampilkan indikator has_next_page daripada total absolut.
Trade-off-nya:
- Lebih efisien untuk dataset besar
- Kurang cocok jika UI benar-benar membutuhkan nomor halaman acak
- Implementasi sedikit lebih kompleks dibanding offset biasa
Contoh perbaikan end-to-end
Misalkan endpoint admin berikut melambat:
-- Query data
SELECT o.id, o.order_number, o.status, c.name
FROM orders o
JOIN customers c ON c.id = o.customer_id
WHERE o.tenant_id = 42
AND o.status = 'paid'
ORDER BY o.created_at DESC
LIMIT 50 OFFSET 5000;
-- Query total
SELECT COUNT(*)
FROM orders o
JOIN customers c ON c.id = o.customer_id
WHERE o.tenant_id = 42
AND o.status = 'paid';Masalahnya:
- Offset besar
- Query count ikut membawa join yang tidak perlu
- Mungkin belum ada composite index yang tepat
Versi yang lebih baik:
CREATE INDEX idx_orders_tenant_status_created_at
ON orders (tenant_id, status, created_at);
-- Query data tetap bisa join jika memang perlu menampilkan nama customer
SELECT o.id, o.order_number, o.status, c.name
FROM orders o
JOIN customers c ON c.id = o.customer_id
WHERE o.tenant_id = 42
AND o.status = 'paid'
ORDER BY o.created_at DESC
LIMIT 50 OFFSET 0;
-- Query count dipisah dan disederhanakan
SELECT COUNT(*)
FROM orders o
WHERE o.tenant_id = 42
AND o.status = 'paid';Jika endpoint ini sangat sering dipakai, tambahkan cache count. Jika nomor halaman tidak wajib, ubah pagination menjadi cursor dan pertimbangkan untuk tidak menampilkan total absolut di setiap request.
Trade-off yang perlu dipahami
Akurasi vs performa
COUNT(*) real-time dan akurat adalah pilihan paling mahal. Cocok jika angka total memang kritis. Jika tidak, cache atau approximate count biasanya lebih rasional.
Index read performance vs write overhead
Menambah index dapat mempercepat query baca, tetapi ada harga yang dibayar saat tulis data. Setiap insert dan update harus menjaga index tetap konsisten. Pada sistem dengan write throughput tinggi, terlalu banyak index bisa menjadi masalah baru.
Kesederhanaan UX vs skalabilitas
Pagination tradisional dengan total halaman terasa familiar, tetapi tidak selalu skalabel. Cursor pagination lebih ramah performa, tetapi mengubah pengalaman pengguna dan cara frontend bekerja.
Kesalahan umum yang perlu dihindari
- Menganggap COUNT(*) selalu murah. Pada tabel kecil mungkin benar, di produksi belum tentu.
- Menyalin query data menjadi query count tanpa penyederhanaan. Ini sering membawa join dan order yang tidak diperlukan.
- Menambah index tanpa melihat pola query nyata. Index harus didesain dari beban kerja aktual, bukan tebakan.
- Hanya melihat query secara terpisah. Bisa jadi satu query tidak terlalu lambat, tetapi dieksekusi ribuan kali per menit.
- Mengabaikan offset besar. Bahkan jika count sudah dioptimalkan, offset yang ekstrem tetap membuat endpoint lambat.
- Meng-cache semua kombinasi filter secara membabi buta. Ini bisa menyebabkan ledakan key cache dan invalidasi yang sulit.
Checklist implementasi di produksi
- Identifikasi endpoint yang menghitung total data di setiap request.
- Ambil SQL final untuk query data dan query
COUNT(*). - Jalankan
EXPLAINatauEXPLAIN ANALYZEpada query count paling mahal. - Pastikan query count tidak membawa
JOIN,ORDER BY, atau kolom yang tidak diperlukan. - Evaluasi composite index berdasarkan pola
WHEREyang paling umum. - Ukur ulang latency endpoint setelah perubahan index atau query.
- Tambahkan cache untuk count yang sering diakses dengan TTL yang realistis.
- Tentukan apakah dashboard atau admin benar-benar membutuhkan count akurat real-time.
- Pertimbangkan approximate count atau tabel summary jika total hanya untuk observasi.
- Evaluasi apakah offset pagination perlu diganti dengan cursor pagination.
Penutup
Mengatasi slow query COUNT(*) pada tabel besar di produksi bukan sekadar soal mengganti satu query, tetapi memahami kenapa database harus membaca terlalu banyak data untuk menghasilkan total yang akurat. Penyebab paling sering adalah filter tanpa index yang tepat, join yang tidak perlu, dan pola pagination yang mahal.
Pendekatan yang biasanya paling efektif adalah kombinasi: sederhanakan query count, buat composite index sesuai pola filter, kurangi frekuensi eksekusi lewat cache, dan gunakan approximate count atau cursor pagination jika kebutuhan bisnis memungkinkan. Fokus utama bukan membuat COUNT(*) selalu instan, melainkan memastikan biaya akurasi itu memang sepadan dengan nilai yang diberikan ke pengguna.
Komentar
0 komentar
Masuk ke akun kamu untuk ikut berkomentar.
Belum ada komentar
Jadilah yang pertama ikut berdiskusi!