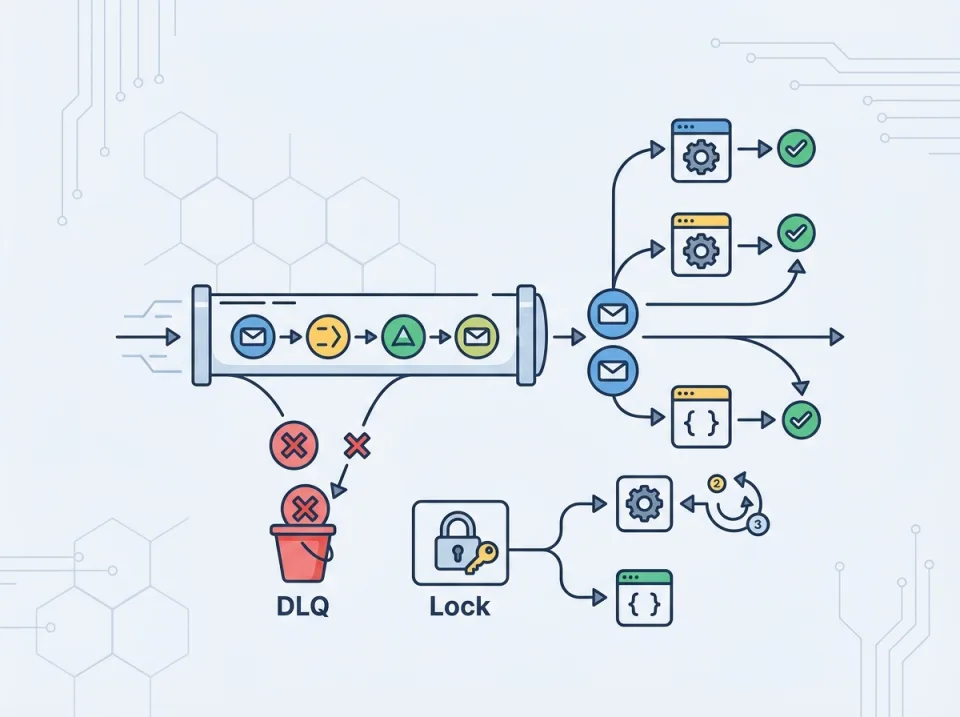

At-least-once queue adalah pola pengantaran pesan yang memprioritaskan keandalan: pesan akan dikirim ulang sampai broker atau worker yakin pemrosesan berhasil. Konsekuensinya, satu job bisa diproses lebih dari sekali. Karena itu, desain worker yang aman tidak boleh mengasumsikan setiap pesan hanya datang sekali.
Dalam praktik operasional, pendekatan yang paling aman bukan mengejar exactly-once di seluruh sistem, melainkan membangun idempotensi, mengatur visibility timeout dan retry dengan baik, menyiapkan dead-letter queue (DLQ), serta menggunakan distributed lock bila ada risiko race condition antar-worker. Artikel ini membahas kapan duplicate terjadi, bagaimana mencegah efek sampingnya, dan checklist operasional yang relevan untuk sistem produksi.
Mengapa job bisa diproses lebih dari sekali?
Pada at-least-once queue, duplicate bukan anomali; duplicate adalah konsekuensi desain. Beberapa penyebab paling umum:
- Worker selesai memproses, tetapi gagal mengirim ack. Dari sudut pandang broker, job terlihat belum selesai sehingga job dikirim ulang.
- Worker crash di tengah proses. Setelah visibility timeout habis, job dianggap tersedia lagi untuk worker lain.
- Network partition atau timeout. Ack sebenarnya terkirim atau tidak terkirim, tetapi salah satu sisi tidak yakin, lalu job diproses ulang.
- Retry dari aplikasi tanpa verifikasi hasil sebelumnya.
- Rebalance/redispatch ketika worker restart, autoscaling, atau terjadi failover.
Intinya, duplicate dapat terjadi meskipun kode bisnis Anda benar. Ia muncul dari kombinasi kegagalan jaringan, crash proses, timeout, dan ketidakpastian status antar-komponen.
Kapan duplicate biasanya terasa paling berbahaya?
Duplicate menjadi masalah ketika handler memiliki side effect yang tidak aman untuk dijalankan dua kali, misalnya:
- Mengirim email yang sama dua kali.
- Mengurangi stok dua kali untuk order yang sama.
- Mencatat transaksi pembayaran ganda.
- Mengirim webhook internal berulang sehingga service downstream memproses event yang sama beberapa kali.
Kalau handler hanya menghitung data sementara di memori, duplicate mungkin tidak berbahaya. Tetapi pada sistem nyata, job queue hampir selalu berinteraksi dengan database, API eksternal, atau state bisnis yang persisten.
Mengapa idempotensi lebih realistis daripada exactly-once?
Exactly-once terdengar ideal: satu pesan diproses tepat satu kali. Masalahnya, pada sistem terdistribusi, jaminan ini sulit dicapai secara end-to-end. Broker mungkin punya fitur tertentu untuk menekan duplicate pada level pengiriman, tetapi begitu handler menyentuh database, cache, HTTP API, email provider, atau service lain, Anda kembali menghadapi kegagalan parsial.
Karena itu, strategi yang lebih aman adalah: anggap duplicate akan terjadi, lalu pastikan hasil akhirnya tetap benar. Inilah inti idempotensi.
Definisi praktis: operasi disebut idempoten jika eksekusi berulang untuk input yang sama menghasilkan keadaan akhir yang setara dengan satu kali eksekusi.
Contoh:
- Tidak idempoten:
stok = stok - 1dieksekusi dua kali untuk order yang sama. - Lebih idempoten: simpan bahwa order
ORD-123sudah pernah mengurangi stok, lalu abaikan eksekusi berikutnya untuk order tersebut. - Idempoten: ubah status invoice menjadi
PAIDberdasarkan transaksi unik, bukan menambah saldo berkali-kali tanpa pengecekan.
Pola idempotensi yang paling berguna
1. Idempotency key
Pola paling umum adalah memberi setiap operasi sebuah idempotency key yang stabil. Kunci ini harus merepresentasikan aksi bisnis, bukan sekadar ID pesan broker yang bisa berubah saat redelivery.
Contoh sumber idempotency key:
order_iduntuk pengurangan stok per order.payment_iduntuk finalisasi pembayaran.email_type:user_id:perioduntuk email ringkasan periodik.event_idyang dihasilkan oleh publisher dan dipertahankan sepanjang alur.
Kunci idempotensi biasanya disimpan di storage yang tahan restart, misalnya database relasional atau key-value store persisten. Saat worker menerima job, worker memeriksa apakah key tersebut sudah pernah diproses.
// pseudocode handler dengan idempotency key
function handleJob(job):
key = job.idempotency_key
if processed_store.exists(key):
ack(job)
return
begin_transaction()
// tulis marker lebih aman bila dikombinasikan dengan transaksi
inserted = processed_store.insert_if_absent(key, status="processing")
if not inserted:
rollback()
ack(job)
return
apply_business_change(job)
processed_store.update(key, status="done", processed_at=now())
commit()
ack(job)Kunci dari pola ini adalah insert-if-absent atau constraint unik. Jangan memakai pola cek dulu lalu insert tanpa proteksi atomik, karena dua worker dapat lolos bersamaan.
2. Dedup berbasis storage
Dedup berbasis storage berarti database atau storage menjadi sumber kebenaran untuk memutuskan apakah suatu operasi sudah pernah dieksekusi. Ini lebih andal daripada hanya mengandalkan memori proses atau cache volatil.
Contoh pendekatan yang umum:
- Unique constraint pada tabel
processed_messagesuntukidempotency_key. - Outbox/inbox table untuk mencatat event yang sudah dikonsumsi.
- Upsert ke tabel status berdasarkan kunci bisnis yang unik.
Contoh skema sederhana:
processed_messages (
idempotency_key varchar primary key,
status varchar not null,
processed_at timestamp null,
response_hash varchar null
)Keuntungan pendekatan ini:
- Tahan restart worker.
- Dapat diaudit.
- Mengurangi ketergantungan pada perilaku broker.
Trade-off-nya:
- Menambah I/O ke storage.
- Perlu desain retensi data agar tabel dedup tidak tumbuh tanpa kontrol.
- Perlu memilih kunci bisnis yang benar; salah memilih key justru bisa mengabaikan operasi valid.
3. Simpan hasil akhir, bukan hanya marker
Untuk sebagian kasus, tidak cukup hanya menandai bahwa job sudah pernah diproses. Kadang Anda juga perlu menyimpan hasil pemrosesan agar redelivery bisa mengembalikan respons yang konsisten.
Misalnya pada webhook internal yang memicu pembuatan invoice. Jika duplicate datang, service dapat membaca hasil sebelumnya dan mengembalikan referensi invoice yang sama, bukan membuat invoice baru atau hanya menjawab "sudah pernah" tanpa konteks.
Visibility timeout, retry, dan backoff
Visibility timeout
Visibility timeout adalah periode saat job yang sedang diambil worker disembunyikan sementara dari worker lain. Jika worker tidak meng-ack sebelum timeout habis, job dianggap gagal dan bisa dikirim ulang.
Konsep ini penting karena dua masalah dapat terjadi sekaligus:
- Terlalu pendek: job masih berjalan, tetapi timeout habis, lalu worker lain memproses job yang sama.
- Terlalu panjang: saat worker crash, job butuh waktu lama untuk diproses ulang sehingga latency pemulihan memburuk.
Praktiknya, visibility timeout harus mempertimbangkan worst-case processing time ditambah buffer. Untuk job yang durasinya sangat bervariasi, beberapa sistem memakai mekanisme heartbeat atau perpanjangan lease saat worker masih sehat.
Retry dengan exponential backoff
Tidak semua kegagalan layak diulang dengan pola yang sama. Retry langsung dan agresif sering memperburuk keadaan, terutama saat dependency sedang lambat atau error.
Gunakan exponential backoff, idealnya dengan jitter, agar retry tersebar dan tidak menyebabkan lonjakan beban serentak.
// pseudocode retry policy
function nextDelay(attempt):
base = 2 seconds
maxDelay = 5 minutes
delay = min(base * (2 ^ attempt), maxDelay)
return addJitter(delay)Panduan praktis:
- Retry untuk error sementara: timeout jaringan, rate limit, service downstream 5xx.
- Jangan retry tanpa batas untuk error permanen: payload invalid, referensi data tidak ada, constraint bisnis gagal.
- Bedakan retryable vs non-retryable sejak awal di handler.
Kesalahan umum adalah memperlakukan semua error sebagai transient. Akibatnya queue penuh oleh job yang tidak akan pernah berhasil.
Diagram alur sederhana
Publisher
|
v
Queue ----> Worker ambil job
|
v
Cek idempotency key
| |
| sudah ada |
v v
ACK Proses bisnis
|
v
Sukses? / Gagal?
| |
v v
ACK Retry dengan backoff
|
v
Melebihi batas retry?
| |
| tidak | ya
v v
Queue DLQDead-letter queue (DLQ): kapan dipakai dan mengapa penting
Dead-letter queue adalah antrian untuk job yang gagal diproses setelah melewati batas retry atau dinilai tidak bisa diproses secara normal. DLQ bukan tempat membuang masalah, tetapi tempat isolasi agar job bermasalah tidak menghambat job sehat.
Kasus yang cocok masuk DLQ
- Payload rusak atau skema tidak valid.
- Data referensi hilang dan tidak mungkin tersedia belakangan.
- Bug aplikasi yang konsisten memicu exception.
- Retry sudah melewati ambang yang wajar.
Operasional DLQ yang sehat
- Sertakan alasan kegagalan terakhir dan jumlah percobaan.
- Sediakan tooling untuk inspect, replay, dan discard.
- Jangan otomatis replay semua isi DLQ tanpa analisis akar masalah.
- Buat alarm bila jumlah pesan DLQ meningkat tajam.
Anti-pattern yang sering terjadi adalah memindahkan job ke DLQ, tetapi tidak ada proses investigasi, dashboard, atau prosedur replay. Akibatnya DLQ berubah menjadi kuburan pesan.
Distributed lock untuk mencegah race pada worker
Idempotensi mengatasi duplicate effect, tetapi tidak selalu cukup untuk race condition. Kadang dua worker memproses entitas yang sama dalam waktu hampir bersamaan dan saling mengganggu, misalnya dua job sinkronisasi stok untuk SKU yang sama.
Dalam kasus seperti ini, distributed lock dapat dipakai untuk membatasi satu worker aktif per resource tertentu, misalnya per product_id, order_id, atau account_id.
Kapan lock diperlukan?
- Operasi pada resource yang sama harus serial.
- Update bersifat non-komutatif dan sensitif urutan.
- Biaya konflik tinggi meskipun idempotensi ada.
Namun lock bukan pengganti idempotensi. Lock mencegah eksekusi paralel yang berbahaya; idempotensi menangani redelivery dan duplicate effect. Keduanya sering dipakai bersama.
Pseudocode lock worker
function handleStockSync(job):
lockKey = "stock-sync:" + job.product_id
token = randomToken()
if not lock.acquire(lockKey, token, ttl=30 seconds):
retryLater(job)
return
try:
if processed_store.exists(job.idempotency_key):
ack(job)
return
syncStock(job)
processed_store.insert_if_absent(job.idempotency_key, status="done")
ack(job)
finally:
lock.release_if_owner(lockKey, token)Aturan penting saat memakai distributed lock
- Gunakan TTL agar lock tidak menggantung selamanya saat worker crash.
- Simpan token owner agar hanya pemilik lock yang boleh melepas lock.
- Jangan membuat lock terlalu lama jika pekerjaan bisa dipecah menjadi langkah lebih kecil.
- Jangan menganggap lock sempurna; tetap siapkan idempotensi bila lease habis atau lock terlepas saat proses masih berjalan.
Distributed lock efektif untuk mengurangi race, tetapi menambah kompleksitas. Pada sebagian kasus, database transaction dengan row-level lock atau constraint unik justru lebih sederhana dan lebih kuat sebagai sumber kebenaran.
Skenario nyata
1. Pengiriman email
Masalah: job kirim email timeout setelah provider menerima request, tetapi sebelum worker menerima respons final. Job di-retry dan email terkirim dua kali.
Pendekatan aman:
- Gunakan idempotency key seperti
email_type:user_id:campaign_id. - Simpan status pengiriman di database, bukan hanya di memori.
- Jika provider mendukung kunci dedup atau custom header, manfaatkan untuk korelasi.
- Batasi retry untuk error yang memang sementara.
2. Sinkronisasi stok
Masalah: dua event untuk SKU yang sama diproses paralel, lalu stok akhir menjadi salah karena update saling menimpa.
Pendekatan aman:
- Pakai lock per
product_idatau serialisasi per partisi kunci. - Simpan event yang sudah diproses berdasarkan
event_id. - Lebih baik gunakan operasi berbasis versi atau compare-and-set jika tersedia.
3. Webhook internal
Masalah: service A mengirim event order berulang karena timeout ke service B. Service B membuat invoice baru setiap kali menerima event yang sama.
Pendekatan aman:
- Service B harus idempoten berdasarkan
event_idatauorder_id + action. - Simpan hasil pembuatan invoice agar duplicate mengembalikan referensi yang sama.
- Masukkan payload invalid ke DLQ, bukan retry terus-menerus.
Implementasi praktis: urutan handler yang aman
- Ambil job dari queue.
- Validasi payload dan klasifikasikan error permanen vs sementara.
- Jika perlu serialisasi per resource, ambil distributed lock dengan TTL.
- Cek idempotency key di storage persisten.
- Gunakan operasi atomik: insert-if-absent, unique constraint, atau transaction.
- Jalankan side effect bisnis.
- Catat hasil akhir dan status sukses.
- Ack job hanya setelah perubahan penting tersimpan dengan aman.
- Jika gagal sementara, retry dengan exponential backoff.
- Jika gagal permanen atau melewati batas retry, kirim ke DLQ.
Metrik yang perlu dipantau
Tanpa metrik, duplicate dan retry sering baru terlihat saat dampaknya sudah menjadi insiden bisnis. Beberapa metrik yang berguna:
- Queue depth: jumlah job menunggu.
- Processing latency: waktu dari enqueue hingga selesai.
- Retry rate: berapa banyak job masuk percobaan ulang.
- DLQ rate: laju job yang berakhir di DLQ.
- Duplicate detection rate: seberapa sering idempotency key terdeteksi sudah pernah diproses.
- Lock contention: frekuensi gagal mendapatkan lock.
- Worker crash/restart count.
- Visibility timeout expirations: indikasi timeout terlalu pendek atau worker lambat.
Jika duplicate detection naik tajam, jangan langsung menyimpulkan sistem aman. Itu bisa menandakan timeout terlalu agresif, ack terlambat, atau dependency eksternal tidak stabil.
Checklist operasional untuk produksi
- Setiap job punya idempotency key yang jelas dan stabil.
- Dedup disimpan di storage persisten, bukan cache semata.
- Handler membedakan error retryable dan non-retryable.
- Retry memakai exponential backoff dan batas maksimum percobaan.
- Ada DLQ beserta prosedur inspeksi dan replay.
- Visibility timeout sesuai durasi proses nyata.
- Untuk resource sensitif, ada distributed lock atau strategi serialisasi lain.
- Ack hanya dilakukan setelah state penting aman tersimpan.
- Ada dashboard untuk queue depth, retry, DLQ, duplicate, dan lock contention.
- Ada uji chaos atau simulasi crash worker di tengah proses.
Anti-pattern yang perlu dihindari
Retry tanpa batas
Ini membuat queue macet oleh job yang tidak mungkin berhasil. Selalu beri batas dan arahkan kasus tertentu ke DLQ.
Lock terlalu lama
TTL lock yang sangat panjang memperlambat pemulihan saat worker mati. TTL terlalu pendek juga berbahaya karena lock bisa habis sebelum pekerjaan selesai. Pilih nilai yang realistis dan pertimbangkan heartbeat bila diperlukan.
Cache dijadikan sumber kebenaran
Menyimpan marker dedup hanya di cache volatil memang cepat, tetapi berisiko hilang saat restart atau eviction. Cache boleh dipakai sebagai akselerator, bukan satu-satunya sumber kebenaran untuk idempotensi bisnis penting.
Cek lalu insert tanpa atomisitas
Pola if not exists then insert tanpa constraint unik atau operasi atomik mudah kalah oleh race condition. Pakai primitive yang menjamin hanya satu pihak menang.
Menggunakan message ID broker sebagai satu-satunya kunci bisnis
ID dari broker belum tentu stabil lintas retry, republish, atau integrasi antar-service. Lebih aman memakai kunci yang mewakili aksi bisnis.
Penutup
Dalam at-least-once queue, duplicate adalah kondisi yang harus diasumsikan, bukan edge case. Cara paling aman untuk mengoperasikan worker di sistem terdistribusi adalah menggabungkan idempotensi, dedup berbasis storage, pengaturan visibility timeout yang masuk akal, retry dengan exponential backoff, DLQ untuk isolasi kegagalan, dan distributed lock saat ada risiko race pada resource yang sama.
Jika Anda harus memilih prioritas implementasi, mulailah dari idempotensi dan klasifikasi error. Setelah itu, rapikan retry, DLQ, dan observabilitas. Exactly-once mungkin menarik secara teori, tetapi di lapangan, sistem yang tahan duplicate dan mudah di-debug hampir selalu lebih berguna.
Komentar
0 komentar
Masuk ke akun kamu untuk ikut berkomentar.
Belum ada komentar
Jadilah yang pertama ikut berdiskusi!