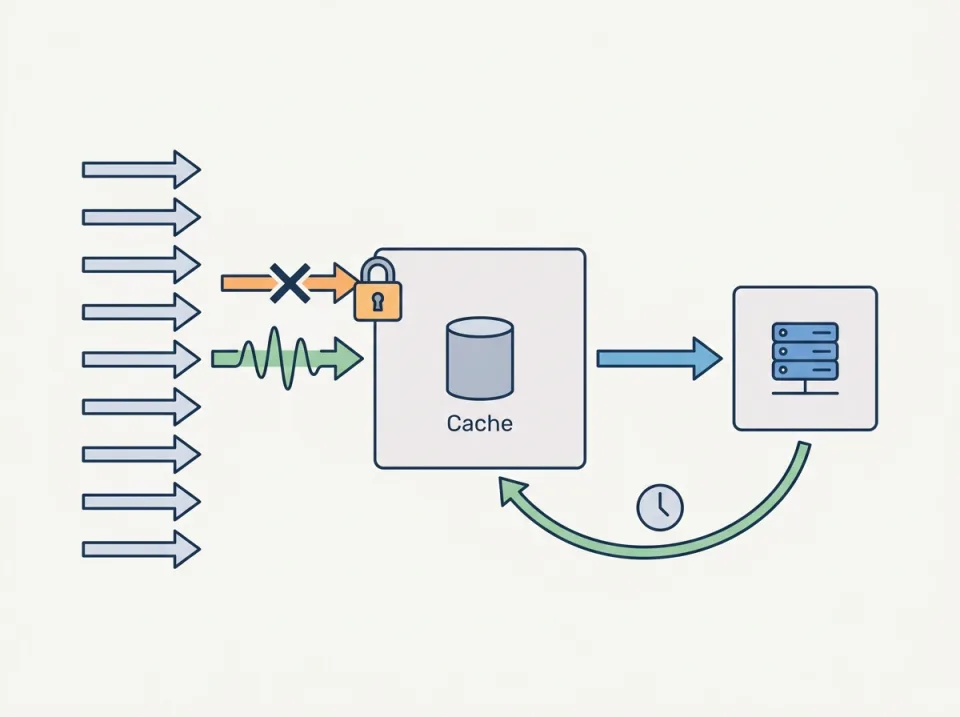

Cache stampede terjadi ketika banyak request meminta data yang sama saat cache habis atau belum terisi, lalu semuanya memicu query atau komputasi mahal secara bersamaan. Pada backend terdistribusi, efeknya cepat terlihat: cache miss melonjak, beban database naik tajam, latency p99 memburuk, dan worker atau thread menumpuk menunggu resource yang sama.
Solusi yang realistis biasanya bukan satu teknik tunggal. Untuk tim backend kecil-menengah, kombinasi Redis lock, single-flight, early recompute, stale-while-revalidate, dan TTL jitter adalah pendekatan yang paling masuk akal: sederhana untuk dioperasikan, cukup aman, dan efektif mengurangi lonjakan beban saat cache kedaluwarsa.
Memahami pola cache stampede
Kasus paling umum terlihat seperti ini:
- Sebuah key cache populer memiliki TTL tetap, misalnya 300 detik.
- Ribuan request bergantung pada key tersebut.
- Saat TTL habis, banyak request datang hampir bersamaan.
- Karena cache kosong, semua request mencoba memuat ulang dari database atau service upstream.
- Database, API internal, atau job worker menerima lonjakan mendadak.
Masalahnya bukan hanya cache miss, tetapi sinkronisasi kegagalan. Bila banyak key dibuat dengan TTL seragam, banyak key juga bisa habis pada waktu yang berdekatan. Ini sering memicu gelombang beban periodik yang terlihat jelas di grafik.
Gejala operasional yang umum
- Lonjakan cache miss pada key populer atau kelompok key yang TTL-nya sama.
- Beban database meningkat, terutama query yang sebenarnya biasa dilindungi cache.
- Latency p95/p99 memburuk walau rata-rata masih tampak normal.
- Worker menumpuk di pool thread, goroutine, proses queue, atau koneksi DB.
- Timeout berantai ke service downstream.
- Retry storm bila klien atau worker otomatis mengulang request yang lambat.
Mengapa Redis lock membantu, dan apa batasannya
Ide dasarnya sederhana: saat cache untuk sebuah key tidak tersedia, hanya satu eksekutor yang diizinkan menghitung ulang nilainya. Request lain menunggu sebentar, mengambil nilai lama, atau gagal secara terkontrol sesuai kebijakan.
Pada Redis, pola paling umum adalah membuat lock per key menggunakan operasi atomik yang setara dengan set-if-not-exists plus expiry. Expiry wajib ada agar lock tidak hidup selamanya jika proses pemegang lock crash.
Kenapa lock efektif
- Mencegah duplikasi kerja: hanya satu proses memukul database untuk key yang sama.
- Mengurangi lonjakan serentak: request lain tidak semuanya masuk ke path mahal.
- Cocok untuk sistem terdistribusi: banyak instance aplikasi bisa berbagi koordinasi lewat Redis.
Trade-off yang perlu dipahami
- Konsistensi vs ketersediaan: menunggu lock bisa menjaga konsistensi hasil, tetapi menambah latency.
- Risiko lock orphan: jika lock dibuat tanpa expiry atau expiry terlalu panjang, key bisa "terkunci" semu.
- Timeout: jika waktu tunggu lock terlalu lama, request menumpuk dan memperburuk p99.
- Deadlock semu: bukan deadlock klasik, tetapi sistem terlihat macet karena banyak request menunggu lock yang tidak relevan lagi atau pemegang lock terlalu lambat.
- Ketergantungan pada Redis: kalau Redis bermasalah, mekanisme anti-stampede juga ikut terdampak.
Catatan: Redis lock bukan peluru perak. Gunakan lock untuk membatasi komputasi ulang, bukan sebagai pengganti desain cache yang baik. TTL jitter, stale-while-revalidate, dan fallback tetap penting.
Pola mitigasi yang realistis
1. Redis lock per cache key
Untuk key populer, buat lock terpisah seperti lock:item:123. Hanya proses yang berhasil memperoleh lock yang boleh memuat ulang data. Proses lain bisa memilih salah satu dari tiga strategi:
- Wait-and-retry: tunggu singkat lalu cek cache lagi.
- Serve stale: kembalikan nilai cache lama jika masih ada.
- Fail fast: jika data tidak kritis, kembalikan fallback terbatas.
Kunci keberhasilannya ada pada expiry lock yang pendek namun cukup, serta pelepasan lock yang aman. Hindari pola delete lock secara buta; idealnya lock memiliki token pemilik, dan hanya pemilik yang boleh menghapusnya.
2. Single-flight di level proses
Walau sudah memakai Redis lock, masih masuk akal menambahkan single-flight di level instance aplikasi. Tujuannya adalah mencegah beberapa worker dalam proses yang sama melakukan kerja duplikat sebelum sempat berkoordinasi dengan Redis.
Single-flight biasanya berupa map in-memory dari key ke promise/future/ongoing computation. Jika ada request kedua untuk key yang sama, ia cukup menunggu hasil komputasi pertama. Ini mengurangi round-trip ke Redis dan menurunkan pressure lokal.
Kapan dipakai: hampir selalu berguna pada service dengan traffic tinggi per instance. Batasannya: ini hanya bekerja dalam satu proses, jadi tidak menggantikan lock terdistribusi.
3. Early recompute
Jangan menunggu cache benar-benar habis. Jika sisa TTL sudah pendek, misalnya tinggal sebagian kecil dari umur normalnya, salah satu request dapat memicu penyegaran lebih awal. Dengan begitu, Anda menghindari momen "semua orang miss sekaligus".
Pola ini efektif bila dipadukan dengan lock: satu request melakukan refresh sebelum kedaluwarsa penuh, sementara request lain tetap memakai nilai cache yang masih valid.
4. Stale-while-revalidate
Stale-while-revalidate berarti data yang sudah melewati TTL utama masih boleh disajikan selama jendela toleransi tertentu, sambil satu proses melakukan refresh di belakang layar. Ini sangat berguna untuk data yang tidak harus selalu paling mutakhir.
Keuntungannya jelas: pengguna tetap mendapat respons cepat, dan backend tidak terpukul oleh miss massal. Trade-off-nya adalah konsistensi: sebagian request bisa menerima data yang sedikit usang.
5. TTL jitter
TTL jitter adalah teknik memberi variasi acak pada TTL agar key tidak habis bersamaan. Misalnya, alih-alih semua key disetel 300 detik, gunakan rentang sekitar 270-330 detik atau formula serupa yang masih sesuai dengan karakter datanya.
Ini salah satu mitigasi paling murah dan sering dilupakan. Tanpa jitter, key populer yang dibuat dalam batch atau saat deploy bisa kedaluwarsa secara serentak, memicu pola stampede periodik.
Alur implementasi yang disarankan
Pendekatan berikut cukup netral bahasa dan cocok untuk banyak backend service:
- Cek cache utama.
- Jika hit dan TTL masih aman, kembalikan nilai.
- Jika hit tetapi mendekati habis, pertimbangkan early recompute.
- Jika miss atau perlu refresh, gunakan single-flight lokal.
- Di dalam single-flight, coba ambil Redis lock per key.
- Jika lock berhasil, ambil data dari sumber asli, tulis ke cache dengan TTL + jitter, lalu lepaskan lock.
- Jika lock gagal, pilih strategi: tunggu singkat lalu cek ulang cache, atau sajikan stale value bila tersedia.
- Jika Redis bermasalah, aktifkan fallback yang lebih sederhana agar service tetap berjalan.
Pseudo-code netral bahasa
function getOrLoad(key):
entry = cache.get(key)
if entry exists and not entry.isExpired():
if entry.remainingTtl() > refreshThreshold:
return entry.value
else:
triggerBackgroundRefreshIfNeeded(key, entry)
return entry.value
staleEntry = cache.getStale(key)
return singleFlight.do(key, function():
fresh = cache.get(key)
if fresh exists and not fresh.isExpired():
return fresh.value
lockToken = redis.tryAcquireLock("lock:" + key, lockTtl)
if lockToken acquired:
try:
data = loadFromOrigin(key)
ttl = baseTtl + randomJitter()
cache.set(key, data, ttl)
cache.setStaleWindow(key, data, staleTtl)
return data
finally:
redis.releaseLockIfOwner("lock:" + key, lockToken)
else:
if staleEntry exists and staleEntry.withinStaleWindow():
scheduleAsyncRetryRefresh(key)
return staleEntry.value
sleep(shortBackoff)
retry = cache.get(key)
if retry exists:
return retry.value
return loadFromOriginWithRateLimitOrFallback(key)
})Beberapa poin penting dari pseudo-code di atas:
- Double-check cache setelah masuk single-flight atau sebelum load dari origin. Bisa jadi request lain sudah lebih dulu mengisi cache.
- Lock punya token pemilik, sehingga pelepasan lock tidak menghapus lock milik proses lain.
- Stale window dipisahkan secara konseptual dari TTL utama.
- Fallback tetap ada jika lock gagal dan Redis atau origin sedang tidak sehat.
Skenario race condition yang sering terjadi
Race 1: Dua instance miss bersamaan
Instance A dan B membaca key yang sama, keduanya miss. A berhasil mengambil lock, B gagal. Jika B langsung memukul database tanpa menunggu, lock tidak ada gunanya. Karena itu, cabang saat gagal lock harus eksplisit: tunggu pendek, cek ulang cache, atau sajikan stale.
Race 2: Lock expired sebelum loader selesai
Misalnya lock TTL terlalu pendek dibanding waktu query yang sesungguhnya. A masih bekerja, lock habis, lalu B memperoleh lock baru dan ikut memuat data. Hasilnya, ada komputasi ganda. Ini bukan selalu fatal, tetapi mengurangi efektivitas lock dan bisa membingungkan metrik.
Mitigasinya:
- Set lock TTL berdasarkan worst-case yang masuk akal, bukan rata-rata.
- Kurangi kerja di dalam area lock.
- Jika perlu, gunakan mekanisme perpanjangan lock dengan hati-hati.
Race 3: Proses crash setelah lock diambil
Tanpa expiry, lock menjadi orphan. Karena itu lock tanpa expiry adalah kesalahan serius. Dengan expiry, sistem akan pulih sendiri, walau request lain mungkin menunggu sampai lock kadaluwarsa.
Race 4: Nilai cache lama menimpa yang baru
Jika ada jalur penulisan yang tidak terkoordinasi, proses lambat bisa menulis hasil lama setelah proses cepat sudah menulis data yang lebih mutakhir. Ini lebih terkait kebijakan penulisan cache daripada lock semata.
Mitigasinya dapat berupa:
- Menyimpan versi atau timestamp sumber data.
- Menghindari menulis cache dari hasil yang sudah jelas usang.
- Menjaga agar refresh cache mengambil snapshot data yang konsisten.
Memilih strategi berdasarkan jenis data
Data boleh sedikit usang
Contoh: katalog, profil publik, konfigurasi yang jarang berubah, agregasi statistik non-kritis. Gunakan kombinasi:
- TTL jitter
- stale-while-revalidate
- early recompute
- Redis lock untuk key panas
Ini biasanya memberi hasil terbaik untuk latency dan kestabilan.
Data harus lebih konsisten
Contoh: status transaksi, kuota yang sensitif, atau aturan akses yang baru berubah. Pendekatan cache masih bisa dipakai, tetapi stale window harus sangat ketat atau tidak dipakai. Lock membantu menghindari stampede, namun latency bisa meningkat karena lebih banyak request harus menunggu hasil refresh.
Untuk jenis data ini, pertimbangkan apakah cache memang tepat, atau apakah event-driven invalidation lebih cocok daripada TTL murni.
Fallback saat Redis bermasalah
Salah satu kesalahan desain adalah menganggap Redis selalu tersedia dan sehat. Padahal saat Redis lambat atau tidak bisa diakses, mekanisme anti-stampede berbasis lock bisa berubah menjadi sumber masalah baru.
Fallback yang masuk akal
- Gunakan single-flight lokal meski lock terdistribusi gagal.
- Sajikan stale value bila risiko konsistensinya masih dapat diterima.
- Batasi request ke origin dengan semaphore lokal, rate limit, atau queue pendek.
- Fail open atau fail closed sesuai domain data. Untuk konten publik sering lebih aman fail open dengan stale. Untuk data sensitif, lebih baik fail closed atau tampilkan respons terkontrol.
Tujuannya bukan menjaga perilaku sempurna, tetapi mencegah kegagalan Redis merambat menjadi kejatuhan database atau seluruh service.
Metrik yang perlu dipantau
Tanpa observabilitas, sulit membedakan cache stampede dari masalah query biasa. Pantau metrik berikut per key panas, endpoint, atau kelompok traffic yang relevan:
- Cache hit ratio dan miss rate.
- Jumlah refresh cache per key atau per endpoint.
- Lock acquisition success/fail.
- Waktu tunggu lock dan jumlah request yang jatuh ke path wait.
- Serve stale count.
- Single-flight join count, yaitu berapa banyak request ikut menunggu kerja yang sama.
- Latency p95/p99 pada endpoint yang memakai cache.
- QPS dan latency database untuk query yang seharusnya dilindungi cache.
- Error rate dan timeout ke Redis serta origin.
- Worker queue depth, thread pool saturation, atau koneksi DB aktif.
Indikator bahwa mitigasi bekerja biasanya terlihat sebagai penurunan lonjakan miss, waktu tunggu lock yang stabil, lebih sedikit query duplikat ke origin, dan p99 yang tidak melonjak saat key populer direfresh.
Kesalahan umum yang sering menyebabkan stampede tetap terjadi
- TTL seragam untuk semua key, terutama key yang dibuat bersamaan.
- Lock tanpa expiry, sehingga orphan lock bisa bertahan lama.
- Menghapus lock tanpa verifikasi pemilik, berisiko melepas lock milik proses lain.
- Lock TTL terlalu pendek, menyebabkan refresh ganda.
- Lock TTL terlalu panjang, membuat request menunggu tidak perlu saat pemegang lock gagal.
- Tidak melakukan double-check cache setelah mendapatkan lock.
- Semua request menunggu lock tanpa batas waktu atau fallback.
- Tidak ada stale path untuk data yang sebenarnya aman disajikan sedikit usang.
- Mengandalkan Redis lock saja tanpa single-flight lokal dan tanpa jitter.
- Menaruh terlalu banyak kerja di area lock, misalnya serialisasi besar atau panggilan tambahan yang tidak perlu.
Checklist rollout aman untuk tim backend kecil-menengah
- Identifikasi key panas atau endpoint dengan miss burst dan p99 buruk.
- Tambahkan TTL jitter terlebih dahulu. Ini perubahan kecil dengan dampak sering signifikan.
- Pasang single-flight lokal untuk mencegah duplikasi kerja dalam satu instance.
- Tambahkan Redis lock hanya pada path mahal, bukan semua key secara membabi buta.
- Tentukan kebijakan stale: boleh atau tidak, berapa lama, dan untuk jenis data apa.
- Set timeout yang eksplisit untuk lock wait dan load dari origin.
- Pastikan lock memiliki expiry dan owner token.
- Instrumentasikan metrik sebelum rollout penuh.
- Uji dengan traffic paralel untuk key yang sama, bukan hanya uji fungsional biasa.
- Lakukan rollout bertahap pada subset endpoint atau persentase traffic.
- Siapkan kill switch untuk menonaktifkan stale mode, early recompute, atau lock path jika ada efek samping.
Contoh kebijakan yang pragmatis
Untuk banyak service backend, kebijakan berikut cukup seimbang:
- Cache utama memakai TTL dasar sesuai kebutuhan data.
- Tambahkan TTL jitter agar waktu kedaluwarsa tidak seragam.
- Jika sisa TTL di bawah ambang tertentu, lakukan early recompute secara oportunistik.
- Gunakan single-flight lokal untuk key yang sama di satu instance.
- Gunakan Redis lock per key hanya selama proses refresh.
- Jika lock gagal, sajikan stale bila masih dalam jendela aman; jika tidak ada stale, tunggu singkat lalu cek ulang cache.
- Jika Redis tidak sehat, jatuh kembali ke single-flight lokal + rate limit ke origin.
Pola ini tidak mengejar konsistensi sempurna, tetapi sangat efektif untuk menjaga sistem tetap stabil saat trafik tinggi dan saat key populer habis masa berlakunya.
Penutup
Mencegah cache stampede dengan Redis lock dan TTL jitter bukan soal menambah lock di mana-mana, tetapi soal mengatur bagaimana cache kedaluwarsa, siapa yang boleh menghitung ulang, dan apa yang dilakukan request lain selama menunggu. Dalam praktik, kombinasi yang paling berguna adalah TTL jitter untuk menghindari sinkronisasi expiry, single-flight untuk mengurangi kerja duplikat, Redis lock untuk koordinasi antar instance, serta stale-while-revalidate dan early recompute untuk menjaga latency tetap rendah.
Jika Anda mulai dari sistem yang sederhana, urutannya jelas: pasang jitter, ukur metrik, tambahkan single-flight, lalu gunakan lock dan stale path hanya pada key atau endpoint yang benar-benar panas. Pendekatan bertahap seperti ini biasanya lebih aman, lebih mudah dioperasikan, dan lebih cocok untuk tim backend kecil-menengah daripada desain yang terlalu kompleks sejak awal.
Komentar
0 komentar
Masuk ke akun kamu untuk ikut berkomentar.
Belum ada komentar
Jadilah yang pertama ikut berdiskusi!