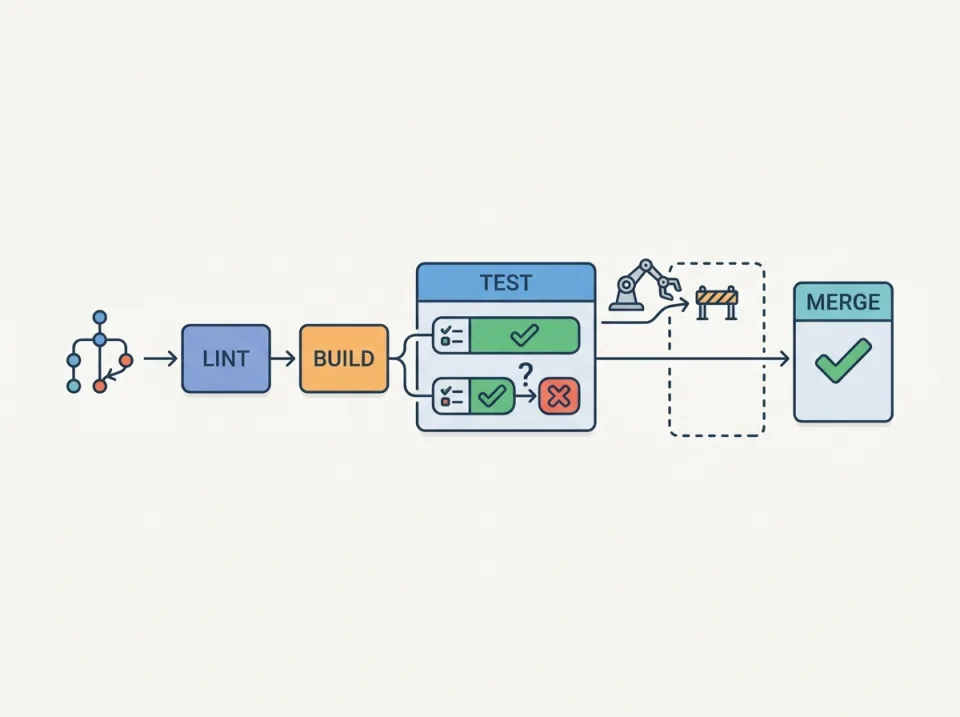

Jawaban Awal: Mengapa validasi automasi penting untuk flaky test?
Strategi validasi automasi yang efektif membantu tim mendeteksi flaky test jauh sebelum kode menyentuh branch utama dengan memantau sinyal-sinyal tidak stabil, menjalankan ulang secara terkontrol, dan mengambil keputusan berbasis metrik. Fokus utamanya adalah menjaga regression gate pada pipeline CI tetap sehat tanpa mengorbankan kecepatan integrasi.
Dalam artikel ini kita langsung membahas bagaimana cara merancang workflow validasi otomatis dengan sinyal khusus, pendekatan retri/quarantine/isolation, integrasi dengan pipeline CI, metrik pengamatan, contoh konfigurasi runner sederhana, dan langkah mitigasi ketika flaky ditemukan.
1. Mengenali sinyal flaky test di awal
Flaky test biasanya memberi sinyal berupa timeout yang tidak konsisten, kesalahan karena data race, atau hasil yang berbeda meskipun inputnya sama. Untuk mengidentifikasi sinyal ini, jalankan tes dalam kondisi terkontrol yang mencatat:
- Timeout: nilai `maxDuration` konsumsi waktu versus baseline sejak build sebelumnya; lonjakan waktu walau tidak ada perubahan logika mengindikasikan possible race atau dependency external.
- Data race atau shared state: pantau tes paralel yang mengakses resource sama (misalnya database temp atau file); gunakan isolation layer untuk mengukur konflik.
- Non-deterministik: hasil yang berfluktuasi berdasarkan seed acak atau waktu; log status lingkungan (timezone, locale, feature flag) untuk membandingkan run.
Catat tiap signal dalam metadata tes agar bisa dilihat dalam tooling observability atau dashboard CI.
2. Pendekatan retri, karantina, dan isolasi
Begitu sinyal terdeteksi, sebaiknya tidak langsung mengabaikan tapi gunakan pendekatan bertingkat:
- Retry terkontrol: jalankan ulang tes yang gagal hingga n kali sebelum menandai build sebagai gagal. Pastikan retry hanya berlaku untuk tes yang diidentifikasi sebagai flaky agar tidak memperpanjang pipeline utama.
- Quarantine: pindahkan tes yang konsisten gagal random ke grup karantina agar tidak memblokir regression gate. Pengelompokan ini memudahkan monitoring tanpa membiarkan mereka mengacaukan hasil utama.
- Isolation: jalankan tes karantina dalam environment khusus (misalnya runner berbeda atau namespace container) untuk mengecek apakah masalah datang dari shared state. Jika isolasi memperbaiki kestabilan, fokus pada cleanup resource atau mocking dependency.
Tujuan pendekatan ini bukan menunda kegagalan, melainkan memberikan data lebih banyak sebelum mengambil keputusan seperti membatalkan merge.
3. Integrasi dengan pipeline CI sebagai regression gate
Pipeline CI harus mengenali lapisan validasi tambahan dengan membagi jobs seperti berikut:
- Unit/Component Test Primary: jalankan sebagai biasa dan langsung memblokir merge jika gagal.
- Flaky Validation Stage: jalankan ulang tes yang gagal selama stage pertama, catat apakah gagal karena timeout/data race, dan identifikasi pattern.
- Merge Gate: hanya izinkan merge jika stage utama dan validation stage tidak menunjukkan sinyal fatal. Tes karantina boleh dijalankan setelah merge atau di jadwal terpisah.
Integrasi ini membuat regression gate memakai data tambahan: misalnya, meski stage utama gagal, pipeline bisa memutuskan "gagal karena sinyal flaky" dan menyimpan hasil untuk analisis tanpa langsung menolak merge. Pastikan setiap runtime pipeline mencatat log rerun, status timeout, dan snapshot lingkungan.
Contoh konfigurasi runner CI sederhana (GitHub Actions)
name: Flaky Validation Workflow
on:
pull_request:
branches: [main]
jobs:
test-core:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Run tests
run: |
./gradlew test
continue-on-error: true
- name: Save test status
run: ./scripts/save-test-status.sh
if: always()
flaky-validation:
needs: test-core
runs-on: ubuntu-latest
if: failure() && needs.test-core.outputs.flakyDetected == 'true'
steps:
- uses: actions/checkout@v4
- run: |
./scripts/rerun-flaky.sh
Dalam contoh di atas, job test-core tidak langsung menghentikan workflow walau gagal; status disimpan untuk menentukan apakah kegagalan disebabkan oleh sinyal flaky. Job flaky-validation hanya berjalan jika sinyal tersebut terdeteksi, menjalankan ulang untuk mengonfirmasi flakiness.
4. Metrik validasi automasi yang harus dicatat
Untuk menilai efektivitas strategi, pantau metrik berikut:
- Durasi rerun: total waktu rerun dibandingkan waktu tes normal; durasi tinggi bisa mengindikasikan sistem tidak stabil atau dependency lambat.
- Pass rate rerun: persentase rerun yang berhasil; angka tinggi menandai tes flaky, angka rendah bisa berarti masalah deterministik.
- Rerun count per tes: tes yang terus-menerus direrun pantau sebagai kandidat karantina.
Metrik ini membantu memprioritaskan perbaikan dan mengetahui kapan harus mengisolasi atau menonaktifkan sementara tes yang bermasalah. Pastikan data ini terlihat di dashboard CI atau sistem observability tim.
5. Langkah mitigasi setelah flaky teridentifikasi
Setelah flaky terdeteksi, rencanakan langkah mitigasi berikut:
- Analisis penyebab: telusuri log timeout, thread dump, atau locked resource. Misalnya, jika data race tercatat, tambahkan lock atau gunakan dependency injection untuk menyuntikkan mock yang thread-safe.
- Perbaiki atau mock dependency: jika flaky berasal dari layanan eksternal, mock respons dalam konteks test untuk menjamin determinisme.
- Tandai dan dokumentasikan: gunakan label di repository (misalnya flake atau quarantine) agar sesi debugging berikutnya tahu statusnya.
- Validasi ulang setelah perbaikan: jalankan tes dalam isolation stage dan bandingkan metrik rerun; pastikan pass rate kembali stabil sebelum menonaktifkan quarantine.
Dokumen mitigasi juga membantu onboarding anggota baru dan menjaga pipeline tetap dapat dipercaya.
Kesimpulan
Strategi validasi automasi yang memprioritaskan deteksi dini flaky test menggabungkan pemantauan sinyal, rerun terkontrol, quarantine, dan metrik yang dapat ditindaklanjuti. Dengan mengintegrasikan pendekatan ini ke dalam pipeline CI dan menyiapkan langkah mitigasi langsung, tim bisa menjaga regression gate tetap akurat tanpa mengorbankan throughput develop.
Komentar
0 komentar
Masuk ke akun kamu untuk ikut berkomentar.
Belum ada komentar
Jadilah yang pertama ikut berdiskusi!