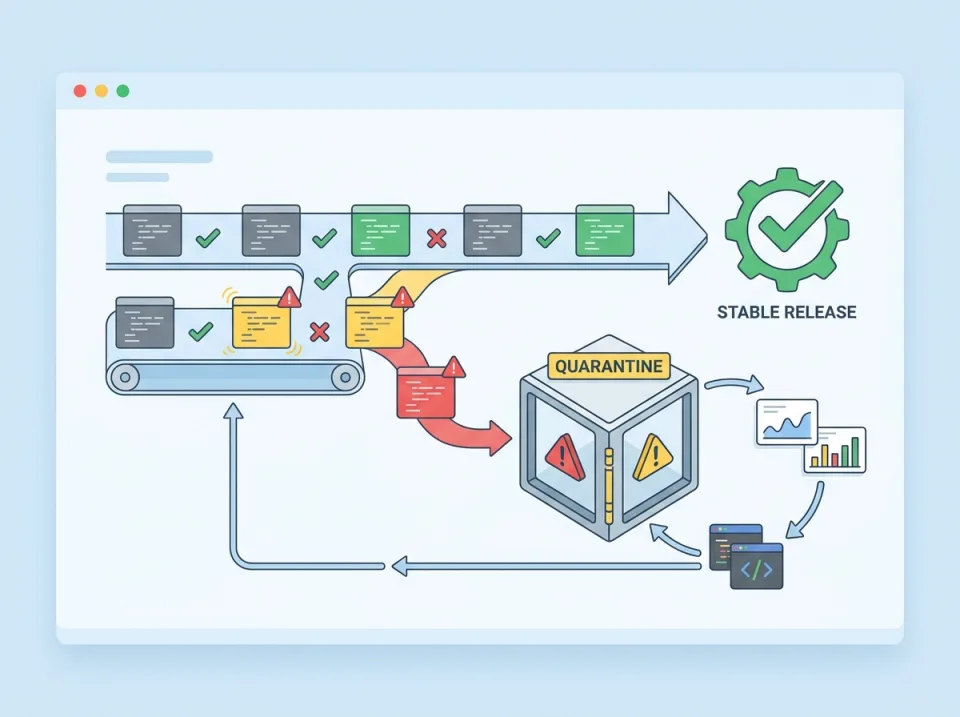

Quarantine flaky test adalah pendekatan untuk memisahkan test yang gagal secara acak dari jalur gate utama CI, sehingga rilis tetap bisa berjalan tanpa mengabaikan masalah. Intinya bukan “mematikan” test, melainkan memindahkannya ke status khusus: tetap dijalankan, tetap terlihat di dashboard, tetap punya owner dan tenggat perbaikan, tetapi tidak langsung memblokir merge atau release.
Masalah utama flaky test bukan hanya pipeline merah. Dampak yang lebih serius adalah turunnya kepercayaan tim terhadap hasil CI. Ketika engineer mulai menganggap kegagalan test sebagai “noise”, bug produk yang nyata bisa ikut terlewat. Karena itu, workflow quarantine harus dirancang ketat: ada kriteria identifikasi, pemisahan antara bug produk dan bug test, aturan ownership, batas waktu, metrik, dan proses unquarantine yang jelas.
Mengapa flaky test berbahaya di CI
Flaky test adalah test yang kadang lolos, kadang gagal, tanpa perubahan kode yang relevan. Penyebabnya beragam: race condition, ketergantungan waktu, data yang tidak terisolasi, network yang tidak stabil, urutan eksekusi test, shared state, atau asynchronous assertion yang rapuh.
Di level CI, efeknya biasanya muncul dalam bentuk:
- False negative: pipeline gagal padahal produk tidak rusak.
- Retry culture: engineer menekan rerun sampai hijau tanpa investigasi akar masalah.
- Lead time meningkat: merge tertunda bukan karena bug riil.
- Signal CI memburuk: tim kehilangan kepercayaan pada status hijau/merah.
Karena itu, tujuan quarantine bukan membuat metrik terlihat lebih baik, melainkan memisahkan sinyal yang tidak dapat dipercaya dari gate utama sambil menjaga akuntabilitas untuk memperbaikinya.
Kapan sebuah test layak dianggap flaky
Jangan terlalu cepat memberi label flaky. Test yang gagal terus-menerus setelah perubahan tertentu bisa jadi justru menemukan bug produk yang valid. Quarantine hanya masuk akal jika ada indikasi kuat bahwa kegagalan bersifat acak atau tidak deterministik.
Sinyal umum flaky test
- Test gagal pada commit A, lalu lolos di rerun tanpa perubahan kode.
- Test hanya gagal pada executor, shard, browser, atau load tertentu.
- Test sensitif terhadap urutan eksekusi.
- Test gagal karena timeout yang tidak konsisten.
- Test E2E/UI gagal karena elemen belum stabil, animasi, atau kondisi rendering yang berubah-ubah.
- Test integration gagal karena dependency eksternal lambat atau tidak sepenuhnya terisolasi.
Cara identifikasi yang lebih aman
Gunakan kombinasi sinyal, bukan satu kejadian tunggal. Praktik yang umum dan cukup aman:
- Ambil riwayat hasil test per nama test case.
- Tandai test yang memiliki pola fail-pass-fail atau pass-fail-pass pada commit yang berdekatan.
- Jalankan rerun terbatas untuk verifikasi, misalnya 3-10 kali pada lingkungan yang sama.
- Lihat apakah failure signature konsisten atau berubah-ubah.
- Periksa apakah ada korelasi dengan environment tertentu: browser, OS, node worker, atau waktu eksekusi.
Catatan: rerun membantu mengonfirmasi ketidakstabilan, tetapi jangan menjadikannya solusi permanen. Jika semua kegagalan selalu “disembuhkan” oleh rerun, masalah dasarnya tetap ada.
Membedakan bug produk vs bug test
Ini bagian paling penting. Quarantine yang buruk sering dipakai untuk menyembunyikan bug produk. Sebelum menandai test sebagai flaky, tim harus menjawab: apakah test ini salah, atau produk memang tidak deterministik?
Indikasi bug produk
- Failure reproduktif pada skenario bisnis tertentu.
- Log, metric, atau tracing menunjukkan error nyata di layanan.
- Pengguna bisa mengalami gejala yang mirip di production.
- Masalah muncul setelah perubahan logic, query, cache, atau concurrency.
Indikasi bug test
- Assertion terlalu sensitif pada timing, urutan, atau representasi yang tidak penting.
- Fixture saling bocor antar test.
- Mock/stub tidak sinkron dengan perilaku nyata sistem.
- Test mengandalkan sleep tetap alih-alih menunggu kondisi yang benar.
- Test UI bergantung pada selector yang rapuh atau state animasi.
Aturan keputusan praktis
Jika ada kemungkinan rasional bahwa perilaku flaky mencerminkan bug yang dialami pengguna, jangan quarantine sebagai default. Perlakukan sebagai defect produk sampai terbukti sebaliknya. Quarantine cocok untuk kasus ketika nilai sinyal test rendah, tetapi test itu masih penting untuk dipantau dan diperbaiki.
Workflow CI untuk quarantine flaky test
Workflow yang efektif harus memenuhi empat tujuan sekaligus:
- Rilis tidak terblokir oleh sinyal yang tidak stabil.
- Test yang di-quarantine tetap dieksekusi dan terlihat.
- Ada owner dan tenggat perbaikan.
- Test bisa kembali menjadi gate setelah stabil.
1. Pisahkan lane gate utama dan lane quarantine
Struktur dasar pipeline:
- Required checks: unit/integration/E2E yang stabil dan dipercaya.
- Quarantine checks: test yang tetap dijalankan, dilaporkan, tetapi tidak menjadi syarat merge.
Pemisahan ini bisa dilakukan dengan tag, manifest, atau daftar test khusus. Yang penting, quarantine tidak hilang dari observabilitas.
2. Tandai test dengan status eksplisit
Jangan hanya memberi komentar di kode. Simpan status test secara terstruktur agar bisa dibaca tooling CI, dashboard, dan bot notifikasi.
Contoh struktur status test dalam file YAML:
tests:
- id: backend.order.checkout_race_condition
path: tests/integration/order/checkout.spec.ts
status: quarantine
reason: "Intermittent failure due to race condition between inventory reservation and payment event"
owner: "team-checkout"
created_at: "2026-04-01"
expires_at: "2026-04-15"
severity: "high"
area: "backend"
gate: false
issue: "QA-241"
- id: frontend.cart.apply_coupon_modal
path: apps/web/e2e/cart/apply-coupon.spec.ts
status: quarantine
reason: "UI assertion flaky due to modal transition timing"
owner: "team-web-platform"
created_at: "2026-04-03"
expires_at: "2026-04-10"
severity: "medium"
area: "frontend"
gate: false
issue: "WEB-882"Field minimum yang disarankan:
- id/path: identitas test yang stabil.
- status: active, quarantine, muted, disabled. Sebisa mungkin batasi status agar tidak membingungkan.
- reason: alasan teknis, bukan catatan umum.
- owner: tim atau individu yang bertanggung jawab.
- expires_at: batas waktu evaluasi/perbaikan.
- gate: apakah memblokir merge/release.
- issue: tiket pelacakan.
3. Jalankan test quarantine di job terpisah
Contoh pola workflow CI yang umum:
jobs:
test-stable:
runs-on: linux
steps:
- checkout
- install
- run: test-runner --exclude-tag quarantine
test-quarantine:
runs-on: linux
steps:
- checkout
- install
- run: test-runner --tag quarantine --report junit --report json
allow_failure: trueNama key CI dan sintaks bisa berbeda tergantung platform, tetapi idenya tetap sama: stable job wajib hijau, sedangkan quarantine job tetap dijalankan dan dilaporkan, namun tidak menjadi gate utama.
Kalau platform CI Anda tidak mendukung allow failure secara eksplisit, alternatifnya adalah:
- menjalankan job quarantine di workflow terpisah yang tidak termasuk required checks, atau
- memproses hasil test quarantine lalu selalu mengembalikan exit code sukses, sambil mengirim hasil detail ke dashboard/notifikasi.
4. Tetapkan owner dan SLA perbaikan
Quarantine tanpa owner hanya memindahkan masalah. Setiap test yang di-quarantine harus memiliki:
- owner yang jelas,
- issue tracker,
- batas waktu perbaikan atau review ulang,
- eskalasi jika melewati tenggat.
Praktik yang baik adalah menolak penambahan quarantine baru jika metadata ini belum lengkap. Bot CI bisa memvalidasi bahwa setiap entry quarantine memiliki owner, issue, dan expiry date.
5. Tetap tampilkan di dashboard dan notifikasi
Kesalahan umum adalah memindahkan test ke quarantine lalu berhenti melihatnya. Dashboard sebaiknya tetap menampilkan:
- jumlah test quarantine aktif,
- failure rate per test,
- umur quarantine,
- tim pemilik,
- tren mingguan,
- test yang sudah melewati expiry.
Jika memungkinkan, bedakan warna/status dari gate utama. Misalnya:
- Green: gate utama lulus.
- Yellow: gate utama lulus, tetapi ada quarantine failure.
- Red: gate utama gagal.
Pola ini menjaga rilis tetap bergerak, tetapi sinyal flaky tidak menghilang.
Contoh implementasi alur di tim backend dan frontend
Contoh alur backend
Misalkan tim backend memiliki integration test untuk alur checkout. Kadang test gagal karena dua event diproses dengan timing berbeda pada worker paralel, tetapi service production sendiri tetap idempotent dan tidak menimbulkan gejala bagi pengguna. Setelah investigasi, tim menyimpulkan penyebabnya adalah test yang bergantung pada urutan event yang terlalu ketat.
- CI mendeteksi test checkout gagal 2 kali dalam 20 run terakhir, tetapi lolos di rerun pada commit yang sama.
- Engineer membuka issue dan menandai test sebagai quarantine.
- Job test-stable tetap memblokir merge, job test-quarantine tidak.
- Dashboard menampilkan failure rate test tersebut.
- Owner backend memperbaiki test dengan menunggu kondisi bisnis final, bukan mengasumsikan urutan log tertentu.
- Setelah beberapa hari stabil, test dipindahkan kembali ke lane utama.
Perbaikan khas pada backend biasanya meliputi:
- menghilangkan shared state antar test,
- menggunakan data unik per run,
- menunggu kondisi eventual consistency dengan polling berbatas, bukan sleep tetap,
- membuat assertion pada state akhir yang relevan bisnis, bukan detail internal yang mudah berubah.
Contoh alur frontend
Pada tim frontend, sebuah E2E test untuk modal kupon belanja kadang gagal karena assertion dijalankan saat animasi belum selesai. Produknya sendiri tidak rusak; masalahnya ada pada strategi sinkronisasi test.
- Test gagal sporadis di browser tertentu saat load tinggi.
- Tim memverifikasi bahwa UI tetap benar jika menunggu elemen benar-benar interaktif.
- Test ditandai sebagai quarantine dengan owner tim web platform.
- CI tetap menjalankan test itu di lane quarantine dan mengirim ringkasan ke Slack atau dashboard internal.
- Perbaikan dilakukan dengan locator yang lebih stabil dan menunggu kondisi DOM/UI yang benar.
Perbaikan khas pada frontend biasanya meliputi:
- menghindari selector berbasis teks yang mudah berubah jika tidak perlu,
- menunggu elemen visible/enabled/stable alih-alih sleep,
- menonaktifkan animasi di environment test jika relevan,
- memastikan data fixture dan network mock deterministik.
Contoh kebijakan quarantine yang bisa langsung dipakai
Checklist kebijakan
- Test hanya boleh di-quarantine jika ada bukti kuat ketidakstabilan, bukan sekadar sekali gagal.
- Bug produk yang masih mungkin berdampak ke pengguna tidak boleh langsung di-quarantine.
- Setiap test quarantine wajib punya owner, issue, alasan teknis, dan expiry date.
- Test quarantine tetap harus dieksekusi secara otomatis di CI.
- Hasil test quarantine wajib terlihat di dashboard dan notifikasi rutin.
- Jumlah test quarantine per tim dipantau dan direview berkala.
- Quarantine yang melewati tenggat harus memicu eskalasi.
- Menonaktifkan test sepenuhnya hanya boleh untuk kasus sangat terbatas dan harus melalui review tambahan.
Status test yang disarankan
Supaya tidak rancu, gunakan status yang sederhana dan konsisten:
- active: test aktif dan menjadi gate.
- quarantine: test aktif, tetap dijalankan, terlihat, tetapi bukan gate utama.
- disabled: test tidak dijalankan sementara; ini sebaiknya jarang dipakai dan perlu persetujuan khusus.
- removed: test dihapus karena tidak lagi relevan.
Hindari status abu-abu seperti ignore, temporary, atau unstable-maybe jika tidak ada definisi operasional yang jelas.
Metrik yang perlu dipantau
Tanpa metrik, quarantine mudah berubah menjadi tempat parkir permanen. Beberapa metrik yang berguna:
- Flake rate per test: persentase gagal acak dibanding total run.
- Quarantine count: jumlah test yang sedang di-quarantine.
- Age of quarantine: umur masing-masing test sejak masuk quarantine.
- Expiry breach: jumlah test yang melewati batas waktu.
- Top noisy suites: suite, folder, atau area yang paling banyak menyumbang flaky test.
- Rerun rate: seberapa sering pipeline harus diulang.
- Mean time to fix: waktu rata-rata perbaikan flaky test.
Interpretasinya juga penting. Misalnya, penurunan jumlah kegagalan CI belum tentu berarti kualitas naik jika ternyata banyak test dipindahkan ke quarantine tanpa penyelesaian. Karena itu, metrik quarantine harus dibaca bersama umur quarantine dan tren unquarantine.
Trade-off dan risiko penyalahgunaan quarantine
Manfaat utama
- Rilis tidak tertahan oleh sinyal yang tidak stabil.
- Tim bisa fokus pada kegagalan yang benar-benar blocking.
- Masalah flaky tetap terlihat dan terukur.
Risiko yang harus diantisipasi
- Menyembunyikan bug produk: label flaky dipakai untuk menghindari investigasi.
- Quarantine bloat: jumlah test quarantine terus bertambah tanpa penyelesaian.
- Moral hazard: engineer lebih cepat mengarantina daripada memperbaiki akar masalah.
- Dashboard fatigue: terlalu banyak sinyal kuning sehingga tetap diabaikan.
Cara mencegah penyalahgunaan
- Batasi siapa yang boleh menyetujui quarantine.
- Wajibkan root-cause hypothesis, bukan hanya label.
- Terapkan expiry date pendek dan review berkala.
- Tampilkan leaderboard atau laporan per tim agar akuntabilitas terlihat.
- Jadikan penurunan quarantine sebagai target kualitas, bukan hanya kestabilan gate.
Kapan test boleh di-unquarantine
Jangan memindahkan test kembali ke gate utama hanya karena “sudah lama tidak gagal”. Gunakan kriteria yang lebih jelas.
Rekomendasi syarat unquarantine
- Akar masalah sudah diidentifikasi dan diperbaiki.
- Test telah melewati sejumlah run berturut-turut tanpa failure acak pada environment yang relevan.
- Tidak ada ketergantungan pada rerun untuk menjadi hijau.
- Jika test pernah flaky karena issue environment, perbaikannya juga sudah tervalidasi di CI sebenarnya, bukan hanya lokal.
- Owner menyetujui bahwa test kembali layak menjadi gate.
Jika tim Anda belum punya ambang numerik baku, jangan memaksakan angka yang terlihat presisi tetapi tidak didukung data. Mulailah dengan review berbasis histori hasil CI beberapa hari atau minggu, lalu standarkan setelah pola tim lebih jelas.
Kesalahan umum saat menerapkan quarantine flaky test
- Menganggap quarantine sama dengan disable.
- Tidak membedakan flaky test dan flaky environment.
- Tidak menyimpan metadata owner dan expiry.
- Tidak mengirim hasil quarantine ke dashboard atau notifikasi.
- Membiarkan test tetap flaky tetapi dipaksa menjadi gate karena dianggap “penting”.
- Memperbaiki gejala dengan sleep lebih panjang, bukan memperbaiki sinkronisasi atau isolasi.
Penutup
Quarantine flaky test yang baik bukan alat untuk menyapu masalah ke bawah karpet, melainkan mekanisme kontrol kerusakan pada CI. Dengan memisahkan lane gate utama dan lane quarantine, menetapkan owner, batas waktu, dashboard, serta aturan unquarantine yang tegas, tim bisa menjaga rilis tetap stabil tanpa kehilangan visibilitas terhadap kualitas test.
Kalau ingin mulai sederhana, lakukan tiga langkah lebih dulu: buat status quarantine yang terstruktur, jalankan test quarantine di job CI terpisah yang tidak memblokir merge, dan wajibkan owner + expiry untuk setiap kasus. Dari sana, tambahkan metrik dan review rutin agar quarantine tetap menjadi alat sementara, bukan kondisi permanen.
Komentar
0 komentar
Masuk ke akun kamu untuk ikut berkomentar.
Belum ada komentar
Jadilah yang pertama ikut berdiskusi!