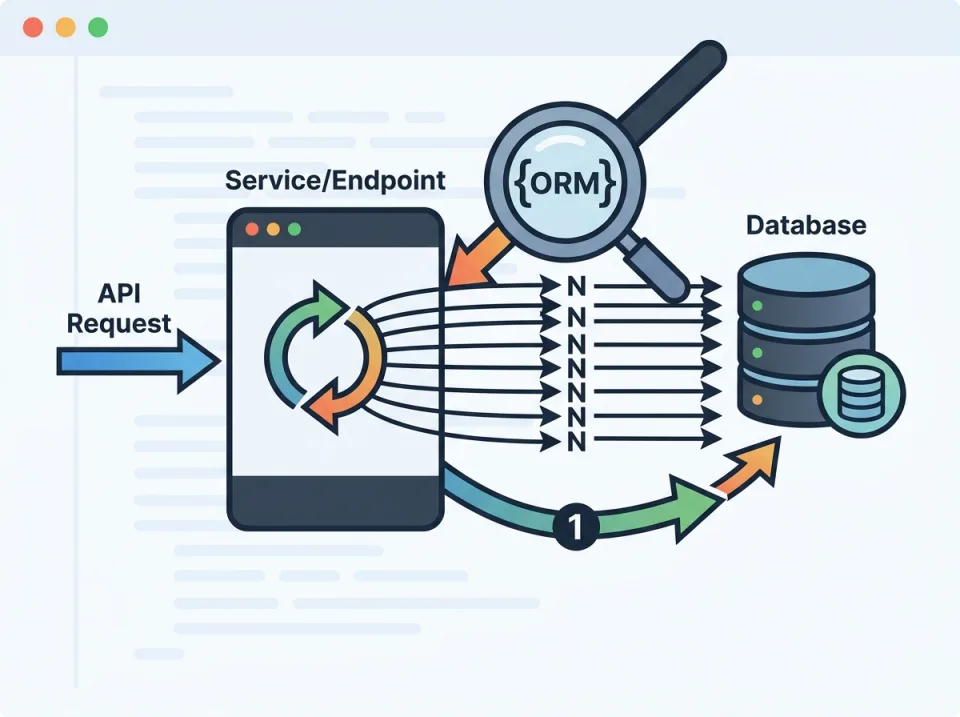

N+1 query adalah salah satu penyebab paling umum API terasa lambat saat data bertambah. Gejalanya sering terlihat jelas di produksi: latency endpoint naik, CPU database tinggi, jumlah query meledak seiring banyaknya item yang dikembalikan, dan APM menampilkan pola query yang sama dieksekusi berulang-ulang.
Pada artikel ini, kita bahas studi kasus debugging backend untuk endpoint API produksi yang terkena N+1 query. Fokusnya bukan hanya mengenali masalah, tetapi juga bagaimana cara membuktikan root cause, mereproduksi bug secara lokal, lalu memperbaikinya dengan pendekatan yang aman: eager loading, batching, memilih field seperlunya, pagination, dan guard test untuk mencegah regresi.
Studi kasus: endpoint list order tiba-tiba melambat
Bayangkan ada endpoint:
GET /api/orders?status=paid&limit=100Endpoint ini mengembalikan daftar order beserta nama customer dan jumlah item. Secara fungsional benar, tetapi beberapa minggu setelah traffic naik, tim mulai melihat tanda-tanda berikut:
- Latency P95 endpoint naik tajam ketika limit diperbesar.
- CPU database meningkat walaupun traffic aplikasi tidak naik secara proporsional.
- Query count per request sangat tinggi dibanding endpoint lain.
- APM menunjukkan banyak query serupa dengan pola parameter berbeda, misalnya
where id = ?dieksekusi berkali-kali.
Di tahap awal, gejala ini sering dikira masalah indeks, ukuran tabel, atau kapasitas database. Padahal, jika pola query berulang muncul dalam satu request, kemungkinan besar penyebab utamanya adalah N+1 query.
Gejala nyata N+1 query di API
1. Latency naik seiring jumlah data yang dikembalikan
Ciri khas N+1 query adalah performa memburuk secara linear atau lebih buruk saat jumlah record utama bertambah. Request dengan 10 order masih terasa cepat, tetapi ketika menjadi 100 atau 500 order, waktu respons naik drastis.
Ini terjadi karena aplikasi tidak hanya menjalankan satu query untuk mengambil daftar order, tetapi juga satu query tambahan untuk tiap order atau relasi di dalamnya.
2. CPU database tinggi walaupun query individual terlihat sederhana
Masalah N+1 sering tidak muncul sebagai satu slow query besar. Justru query-query kecil yang dieksekusi sangat banyak akan menghabiskan CPU, connection pool, dan waktu parsing/eksekusi di database.
Akibatnya, meskipun setiap query tampak ringan, total bebannya berat karena jumlahnya besar dalam satu request dan terakumulasi di banyak request paralel.
3. Query count meledak saat volume data bertambah
Jika untuk 20 data ada 21 query, untuk 100 data ada 101 query, itu pola yang sangat kuat ke arah N+1. Dalam banyak kasus, jumlah query bisa lebih parah lagi jika ada relasi bertingkat, misalnya order -> customer -> address, atau order -> items -> product.
4. Log APM menampilkan pola query berulang
Tool APM biasanya memperlihatkan query yang sama dipanggil berkali-kali, misalnya:
select * from customers where id = ? limit 1Jika query seperti ini muncul puluhan atau ratusan kali dalam satu trace request, hampir pasti ada akses relasi secara lazy loading atau query manual di dalam loop.
Langkah investigasi: dari produksi ke reproduksi lokal
1. Mulai dari trace APM per endpoint
Pilih satu endpoint yang jelas bermasalah, lalu lihat trace request-nya. Hal yang dicari:
- Total waktu request.
- Jumlah query database dalam satu request.
- Distribusi waktu: aplikasi, database, jaringan, serialisasi response.
- Pola query berulang dengan struktur yang sama.
Tujuannya adalah memastikan bottleneck benar-benar berasal dari akses database, bukan dari rendering JSON, external API, atau bottleneck lain.
2. Cocokkan dengan slow query log
Slow query log tetap berguna, tetapi untuk kasus N+1 ada keterbatasan: sering kali masing-masing query tidak cukup lambat untuk masuk kategori slow. Namun log ini masih membantu untuk:
- Menemukan query yang dipanggil sangat sering.
- Melihat apakah ada query tambahan yang muncul berulang dalam rentang waktu yang sama.
- Memastikan tidak ada masalah lain seperti full table scan besar atau query tanpa indeks.
Jika tidak ada satu query yang sangat lambat, tetapi jumlah query per request sangat tinggi, itu justru menguatkan dugaan N+1.
3. Aktifkan query log atau profiling ORM di lingkungan aman
Setelah ada kandidat endpoint, reproduksi di staging atau lokal dengan data yang cukup representatif. Aktifkan logging query dari ORM atau database layer, lalu hit endpoint yang sama.
Yang dicari bukan hanya durasi, tetapi urutan query. Contoh pola yang mencurigakan:
- Query pertama mengambil 100 order.
- Lalu muncul 100 query terpisah untuk mengambil customer masing-masing order.
- Kemudian muncul lagi query tambahan untuk item atau product dari tiap order.
Urutan seperti ini jauh lebih informatif dibanding hanya melihat total latency.
4. Reproduksi dengan dataset yang cukup besar
N+1 sering lolos di development karena data lokal terlalu sedikit. Endpoint dengan 5 record terlihat baik-baik saja, padahal di produksi memproses 200 record per request.
Saat reproduksi lokal, pastikan:
- Jumlah data mendekati kondisi produksi atau minimal cukup besar untuk memunculkan pola.
- Relasi data realistis, misalnya tiap order punya customer dan beberapa item.
- Pagination dan filter yang sama dengan request produksi juga diterapkan.
Jika bug hanya muncul ketika
limit=100atau ketika filter tertentu aktif, reproduksi harus mengikuti kondisi itu. Menguji dengan dataset kecil sering menghasilkan kesimpulan yang salah.
Root cause teknis: mengapa N+1 query terjadi
Lazy loading pada relasi
Root cause paling umum adalah lazy loading. ORM sering memudahkan akses relasi seperti properti biasa. Misalnya, developer mengambil daftar order lalu di loop mengakses order.customer.name. Jika relasi customer belum diambil sebelumnya, ORM akan menjalankan query baru untuk setiap order.
Secara kode, ini terlihat bersih dan mudah dibaca. Masalahnya, satu baris akses properti di dalam loop bisa berubah menjadi ratusan query tambahan.
Query manual di dalam loop
N+1 tidak selalu berasal dari ORM. Kadang penyebabnya query manual seperti:
for each order in orders:
customer = query("select * from customers where id = ?", order.customer_id)Polanya sama: satu query untuk data utama, lalu satu query per item untuk data relasi atau agregasi tambahan.
Relasi bertingkat memperparah masalah
Masalah menjadi lebih berat jika API membangun response yang kaya, misalnya:
- Order memuat customer
- Customer memuat address
- Order memuat items
- Setiap item memuat product
Jika semua diakses secara lazy di dalam loop, jumlah query dapat meningkat sangat cepat. Inilah alasan endpoint yang terlihat sederhana bisa tiba-tiba menjadi sumber beban database besar.
Contoh pseudo-code sebelum dan sesudah
Sebelum: query di dalam loop
// Ambil order utama
orders = OrderRepository.findPaid(limit=100)
response = []
for order in orders:
customer = CustomerRepository.findById(order.customer_id)
items = ItemRepository.findByOrderId(order.id)
response.append({
"id": order.id,
"customer_name": customer.name,
"item_count": len(items),
"total": order.total_amount
})
return responsePola di atas menghasilkan:
- 1 query untuk order
- N query untuk customer
- N query untuk items
Totalnya menjadi 1 + N + N. Untuk 100 order, itu bisa menjadi 201 query hanya untuk satu request.
Sesudah: eager loading dan agregasi lebih awal
// Ambil order beserta customer dan item count sekaligus
orders = OrderRepository.findPaidWithCustomerAndItemCount(limit=100)
response = []
for order in orders:
response.append({
"id": order.id,
"customer_name": order.customer.name,
"item_count": order.item_count,
"total": order.total_amount
})
return responsePada versi perbaikan, relasi dan agregasi sudah disiapkan sejak awal. Hasilnya:
- Jumlah query jauh lebih sedikit.
- Loop hanya menyusun response, bukan mengambil data tambahan.
- Performa lebih stabil saat jumlah order bertambah.
Perbaikan yang bisa diterapkan
1. Gunakan eager loading untuk relasi yang pasti dipakai
Eager loading berarti mengambil relasi sekaligus saat query utama dijalankan. Pendekatan ini paling tepat jika endpoint memang selalu membutuhkan relasi tertentu, misalnya customer untuk setiap order.
Kenapa ini bekerja? Karena ORM atau query builder dapat mengelompokkan pengambilan data relasi menjadi satu query tambahan terstruktur, atau melakukan strategi join yang lebih efisien, alih-alih query per item.
Trade-off-nya:
- Jika terlalu banyak relasi dieager-load, payload data dan memori aplikasi bisa membesar.
- Tidak semua relasi perlu dimuat; pilih hanya yang benar-benar dipakai di response.
2. Batching untuk data yang tidak cocok dijoin langsung
Ada kasus di mana eager loading penuh tidak ideal, misalnya ketika data tambahan berasal dari sumber lain, butuh agregasi khusus, atau lebih efisien diambil terpisah. Solusinya adalah batching:
- Kumpulkan semua
customer_iddari daftar order. - Ambil customer dengan satu query
where id in (...). - Buat map
customer_id -> customer. - Gunakan map itu saat membangun response.
Batching mengurangi query dari N menjadi 1 atau beberapa query terkontrol.
3. Pilih field seperlunya
Saat memperbaiki N+1, jangan sekadar mengambil semua kolom dari semua tabel. Jika endpoint hanya butuh nama customer dan total order, ambil field yang relevan saja.
Ini penting karena setelah N+1 diperbaiki, bottleneck berikutnya sering bergeser ke ukuran hasil query, transfer data dari database ke aplikasi, dan proses serialisasi JSON.
4. Terapkan pagination yang realistis
N+1 menjadi lebih terasa ketika endpoint mengembalikan terlalu banyak data sekaligus. Walaupun eager loading sudah diterapkan, mengirim ratusan atau ribuan record dengan banyak relasi tetap mahal.
Pagination membantu membatasi:
- Jumlah row yang diproses per request.
- Ukuran response.
- Tekanan pada database dan application server.
Pagination bukan pengganti perbaikan N+1, tetapi lapisan proteksi tambahan agar endpoint tidak dipakai secara berlebihan.
5. Gunakan agregasi di query, bukan hitung di loop
Jika API butuh jumlah item, total, atau statistik sederhana, lebih baik hitung di database melalui agregasi atau subquery yang terkontrol daripada mengambil semua child rows lalu menghitungnya satu per satu di aplikasi.
Ini bukan hanya mengurangi query, tetapi juga mengurangi data yang perlu dipindahkan ke aplikasi.
Contoh pendekatan batching
orders = OrderRepository.findPaid(limit=100)
customerIds = unique(map(order => order.customer_id, orders))
customers = CustomerRepository.findByIds(customerIds)
customerMap = toMap(customers, key="id")
itemCounts = ItemRepository.countGroupedByOrderIds(map(order => order.id, orders))
response = []
for order in orders:
customer = customerMap[order.customer_id]
response.append({
"id": order.id,
"customer_name": customer.name,
"item_count": itemCounts.get(order.id, 0),
"total": order.total_amount
})Pendekatan ini cocok ketika Anda ingin mengontrol query secara eksplisit tanpa terlalu bergantung pada perilaku default ORM.
Checklist diagnosis N+1 query
- Apakah latency naik seiring jumlah item di response?
- Apakah query count per request meningkat hampir linear terhadap jumlah data?
- Apakah APM menunjukkan query identik berulang dengan parameter berbeda?
- Apakah ada akses relasi ORM di dalam loop?
- Apakah ada query manual di dalam loop atau mapper/serializer?
- Apakah response builder memicu lazy loading tanpa disadari?
- Apakah reproduksi lokal menggunakan dataset yang cukup besar?
- Apakah setelah eager loading jumlah query turun signifikan?
Guard test untuk mencegah regresi
Bug N+1 mudah kembali muncul saat endpoint berkembang. Misalnya, ada developer menambahkan field baru ke serializer yang tanpa sadar mengakses relasi tambahan. Karena itu, perbaikannya sebaiknya diikuti guard test.
1. Test jumlah query maksimal
Jika stack Anda mendukung query counting pada test, buat test yang mengeksekusi endpoint dengan dataset tertentu lalu memverifikasi jumlah query tidak melewati ambang yang masuk akal.
// pseudo-test
seedOrders(count=50, withCustomer=true, withItems=true)
startQueryCount()
response = callApi("GET", "/api/orders?status=paid&limit=50")
queryCount = stopQueryCount()
assert response.status == 200
assert queryCount <= expectedMaxQueriesAngka ambang tidak harus terlalu agresif, tetapi cukup untuk mendeteksi lonjakan query yang tidak wajar.
2. Test skala data, bukan hanya hasil JSON
Pastikan ada test dengan jumlah data lebih dari satu atau dua record. N+1 sering tidak terlihat jika test hanya memakai data minimal.
3. Review serializer dan mapper
Di banyak codebase, query tersembunyi bukan di service utama, tetapi di lapisan transformasi response. Menambahkan review test pada lapisan ini sering membantu.
Kesalahan umum saat memperbaiki N+1
- Memperbaiki dengan join besar tanpa seleksi field: query count turun, tetapi memori dan payload naik tajam.
- Meng-eager-load semua relasi: aman dari N+1, tetapi boros jika banyak data tidak dipakai.
- Hanya melihat slow query tunggal: padahal masalahnya justru banyak query kecil.
- Menguji di lokal dengan 5 data: hasilnya terlihat cepat, sementara produksi gagal di 500 data.
- Mengabaikan serializer: service sudah benar, tetapi serializer memicu lazy loading baru.
Pelajaran operasional untuk developer backend
1. Pantau query count per endpoint
Selain latency, query count adalah sinyal operasional yang sangat berguna. Endpoint dengan query count tinggi cenderung rapuh terhadap pertumbuhan data.
2. Anggap akses relasi di loop sebagai red flag
Setiap kali melihat loop yang mengakses relasi, berhenti sejenak dan tanyakan: apakah ini akan memicu lazy loading? Kebiasaan review seperti ini efektif mencegah masalah sejak code review.
3. Jadikan performa bagian dari definisi selesai
Untuk endpoint list, definisi selesai sebaiknya tidak hanya “response benar”, tetapi juga mencakup:
- Pagination diterapkan.
- Relasi yang dibutuhkan dimuat dengan benar.
- Jumlah query terkendali.
- Test regresi tersedia.
4. Reproduksi dengan data realistis
Bug performa jarang muncul di dataset kecil. Seed data yang representatif adalah alat debugging yang sama pentingnya dengan log dan APM.
Penutup
Debugging N+1 query di API sebaiknya dimulai dari gejala yang terukur: latency naik, CPU database tinggi, query count meledak, dan trace APM menunjukkan query berulang. Dari sana, investigasi bisa dipersempit ke akses relasi lazy loading atau query di dalam loop, lalu dibuktikan melalui query log dan reproduksi lokal dengan dataset yang cukup besar.
Perbaikan yang paling sering efektif adalah eager loading, batching, memilih field seperlunya, menambahkan pagination, dan memasang guard test untuk menjaga jumlah query tetap terkendali. Yang penting, jangan berhenti di level “sudah lebih cepat”; pastikan penyebab teknisnya benar-benar dipahami agar pola yang sama tidak kembali muncul di endpoint lain.
Komentar
0 komentar
Masuk ke akun kamu untuk ikut berkomentar.
Belum ada komentar
Jadilah yang pertama ikut berdiskusi!