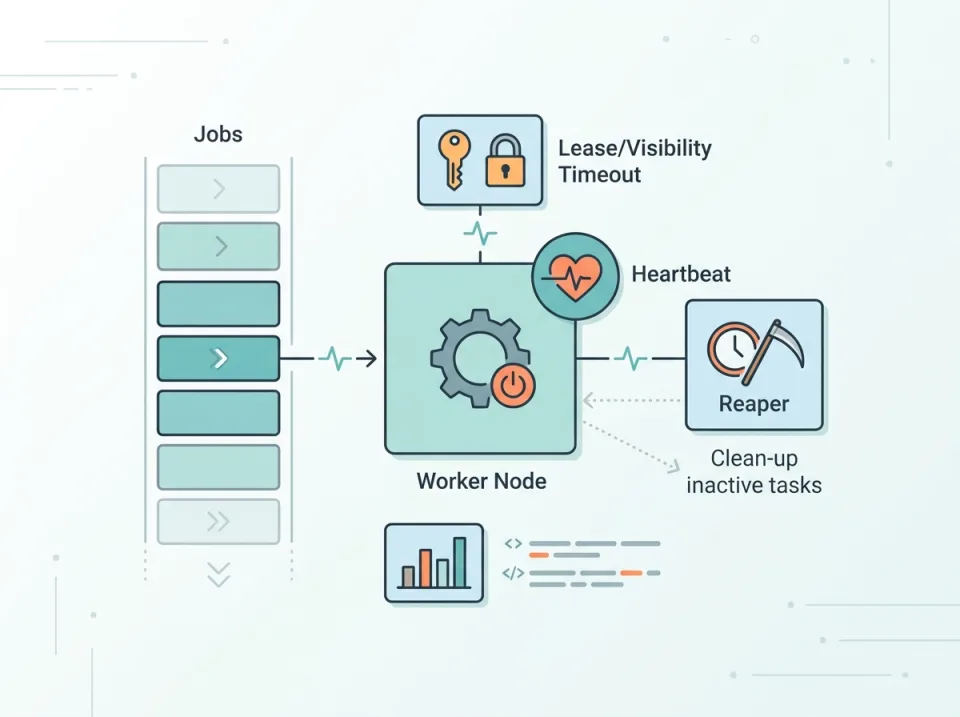

Job zombie muncul ketika sebuah job terlihat sedang diproses, tetapi worker yang memegangnya sudah mati, hang, terputus dari broker, atau berhenti memperbarui status. Akibatnya, job tidak selesai, tidak bisa diambil ulang, atau justru diproses dua kali jika mekanisme recovery terlalu agresif.
Untuk mencegah kondisi ini, Anda biasanya membutuhkan kombinasi lease atau visibility timeout, heartbeat dari worker, dan reaper yang secara berkala mendeteksi job yang benar-benar terlantar. Kuncinya bukan hanya bisa mengambil ulang job, tetapi melakukannya dengan aman agar tidak memperparah duplicate execution atau menandai job sehat sebagai zombie.
Apa itu job zombie dan mengapa sulit ditangani?
Istilah job zombie mengacu pada job yang statusnya tidak lagi mencerminkan kenyataan operasional. Contoh paling umum:
- Worker crash setelah menandai job sebagai running, tetapi sebelum ack atau complete.
- Worker hang karena deadlock, blocking I/O, GC pause panjang, atau dependency eksternal macet.
- Koneksi ke broker atau database putus, sehingga worker masih hidup tetapi tidak lagi bisa memperbarui metadata.
- Recovery terlalu cepat, sehingga job yang sebenarnya masih berjalan dianggap mati dan diambil worker lain.
Masalah ini sulit karena sistem terdistribusi tidak bisa membedakan secara sempurna antara:
- worker benar-benar mati,
- worker masih hidup tetapi sangat lambat,
- network partition,
- broker lambat memproses update status.
Karena itu, desain yang baik tidak pernah bergantung pada satu sinyal saja. Jangan hanya mengandalkan status running di database, dan jangan hanya mengandalkan timeout tanpa idempotensi.
Istilah penting: lock, lease, visibility timeout, dan heartbeat
Lock
Lock biasanya berarti hak eksklusif untuk mengakses resource tertentu. Dalam konteks queue, lock sering dipakai agar hanya satu worker yang boleh memproses job tertentu pada saat yang sama.
Masalahnya, lock murni bisa berbahaya jika tidak punya masa berlaku. Jika worker mati saat lock masih aktif, job bisa tertahan selamanya. Karena itu, lock yang aman di sistem terdistribusi hampir selalu perlu expiry atau dibentuk sebagai lease.
Lease
Lease adalah lock yang memiliki masa berlaku terbatas. Worker memegang hak memproses job hanya sampai waktu tertentu, misalnya lease_expires_at. Jika worker masih sehat, lease diperpanjang lewat heartbeat. Jika tidak, lease akan habis dan job bisa diambil ulang.
Lease cocok ketika Anda menyimpan status job di database atau storage sendiri dan membutuhkan kontrol eksplisit atas kepemilikan job.
Ringkasnya: lock menjawab “siapa yang memegang job sekarang”, sedangkan lease menjawab “siapa yang memegang job sekarang dan sampai kapan”.
Visibility timeout
Visibility timeout adalah konsep yang umum pada message broker atau queue managed service. Saat worker mengambil pesan, pesan tidak langsung dihapus, tetapi disembunyikan sementara dari worker lain. Jika worker sukses, ia menghapus atau meng-ack pesan. Jika tidak, setelah timeout habis pesan akan muncul lagi.
Secara praktis, visibility timeout adalah bentuk lease yang dikelola oleh sistem queue. Ini sangat berguna karena failure recovery terjadi otomatis tanpa harus membuat scheduler reaper yang terlalu kompleks. Namun tetap ada trade-off:
- Jika timeout terlalu pendek, duplicate execution meningkat.
- Jika terlalu panjang, recovery lambat saat worker benar-benar mati.
- Job panjang biasanya butuh mekanisme extend visibility timeout atau heartbeat ke broker.
Heartbeat
Heartbeat adalah sinyal periodik dari worker yang menyatakan “saya masih hidup dan masih mengerjakan job ini”. Heartbeat biasanya memperbarui:
last_heartbeat_at,lease_expires_at,- opsional: progres atau checkpoint,
- opsional: metadata host, pid, atau instance id.
Heartbeat tidak otomatis menyelesaikan job zombie, tetapi memberi sinyal yang lebih akurat bagi reaper untuk membedakan job terlantar dari job lambat yang masih sehat.
Kapan memakai masing-masing mekanisme?
Pakai lock saja jika benar-benar singkat dan lokal
Lock sederhana cukup untuk operasi yang sangat pendek dan failure domain kecil, misalnya mencegah dua thread di proses yang sama menjalankan handler yang sama. Untuk sistem queue lintas worker atau lintas node, lock tanpa expiry hampir selalu tidak cukup.
Pakai lease jika Anda mengelola antrian atau metadata sendiri
Lease cocok ketika:
- job disimpan di tabel database atau storage internal,
- Anda ingin kontrol penuh atas recovery policy,
- Anda butuh reaper yang mempertimbangkan aturan bisnis tertentu.
Dengan lease, Anda bisa membuat perilaku yang lebih dapat diprediksi, tetapi Anda juga harus menangani lebih banyak edge case sendiri.
Pakai visibility timeout jika broker sudah menyediakannya
Jika queue Anda punya konsep invisibility dan ack, manfaatkan itu sebagai fondasi utama. Tambahkan heartbeat atau extension bila job bisa berjalan lebih lama dari timeout standar.
Jangan menduplikasi mekanisme secara sembarangan. Misalnya, memakai visibility timeout dari broker lalu menambahkan status running di database tanpa sinkronisasi yang jelas justru bisa menciptakan dua sumber kebenaran.
Pakai heartbeat jika durasi job tidak stabil atau panjang
Heartbeat sangat berguna ketika:
- durasi job sulit diprediksi,
- job bisa berjalan beberapa menit atau jam,
- Anda ingin deteksi dini worker hang,
- Anda perlu observabilitas progres kerja.
Namun heartbeat bukan pengganti idempotensi. Worker bisa heartbeat tepat sebelum crash, lalu job tetap harus diambil ulang nanti.
Failure mode utama yang harus diantisipasi
Duplicate execution
Duplicate execution terjadi ketika job yang sama diproses lebih dari sekali. Ini bisa disebabkan oleh:
- lease habis saat worker lama sebenarnya masih berjalan,
- ack sukses di worker tetapi gagal tercatat di broker atau database,
- reaper terlalu cepat me-requeue job,
- worker retry setelah timeout tetapi side effect sebelumnya sudah sempat terjadi.
Karena itu, desain queue yang sehat harus mengasumsikan at-least-once delivery. Artinya, handler job harus sedapat mungkin idempotent.
Stuck job
Stuck job adalah job yang tidak membuat progres, tetapi tidak pernah diambil ulang. Penyebab umum:
- lease tidak pernah kedaluwarsa,
- heartbeat thread ikut hang bersama thread utama,
- reaper terlalu konservatif,
- status job tidak pernah dibersihkan setelah deploy atau crash.
Recovery terlalu agresif
Recovery agresif terlihat bagus di dashboard karena antrean cepat “pulih”, tetapi risikonya besar:
- dua worker memproses job yang sama bersamaan,
- side effect eksternal terjadi dua kali,
- sistem downstream menerima request duplikat,
- troubleshooting makin sulit karena log berasal dari dua eksekusi berbeda.
Aturan praktis: lebih baik recovery sedikit terlambat daripada terlalu cepat jika job tidak sepenuhnya idempotent. Sebaliknya, bila job sangat idempotent dan backlog mahal, Anda bisa memilih timeout yang lebih agresif.
Desain minimal yang aman: metadata job dan status worker
Implementasi lintas stack bisa berbeda, tetapi skema metadata minimal berikut cukup umum dan praktis.
Skema tabel job minimal
jobs
----
id string / uuid
queue_name string
payload json / blob
status enum(pending, running, completed, failed)
attempt_count integer
max_attempts integer
available_at timestamp
started_at timestamp nullable
completed_at timestamp nullable
failed_at timestamp nullable
last_heartbeat_at timestamp nullable
lease_expires_at timestamp nullable
locked_by string nullable
lock_token string nullable
idempotency_key string nullable
last_error text nullable
created_at timestamp
updated_at timestampKeterangan penting:
locked_by: identitas worker atau instance.lock_token: token unik per pengambilan job. Ini penting agar worker lama tidak bisa menimpa update worker baru.lease_expires_at: batas waktu kepemilikan job saat ini.last_heartbeat_at: observabilitas dan dasar keputusan reaper.attempt_count: melacak pengambilan ulang dan retry.idempotency_key: membantu menahan side effect ganda.
Mengapa lock_token penting?
Tanpa lock_token, skenario berikut berbahaya:
- Worker A mengambil job dan memulai proses.
- Heartbeat terlambat, lease habis.
- Worker B mengambil job yang sama.
- Worker A “hidup kembali” lalu mengubah status menjadi completed.
Jika update hanya berdasarkan job_id, Worker A bisa menimpa kepemilikan Worker B. Dengan lock_token, semua update sensitif harus memakai syarat WHERE id = ? AND lock_token = ?. Jadi hanya pemilik lease saat ini yang boleh heartbeat, complete, atau fail.
Alur worker yang aman
1. Klaim job secara atomik
Worker harus mengambil job dan menandainya sebagai running dalam satu langkah atomik, atau sedekat mungkin dengan atomik sesuai storage yang dipakai.
function claimJob(workerId, now, leaseDuration):
token = randomToken()
job = atomically find one job where:
status = 'pending'
and available_at <= now
order by available_at asc
if no job:
return null
update that job:
status = 'running'
started_at = now
last_heartbeat_at = now
lease_expires_at = now + leaseDuration
locked_by = workerId
lock_token = token
attempt_count = attempt_count + 1
return job + tokenJika queue Anda memakai broker dengan ack dan visibility timeout, langkah ini biasanya digantikan oleh operasi receive dari broker. Namun Anda tetap bisa menyimpan metadata tambahan di storage sendiri.
2. Jalankan heartbeat terpisah dari logika utama
Heartbeat idealnya dijalankan oleh mekanisme terpisah dari handler utama, misalnya thread ringan, goroutine, atau loop periodik non-blocking. Tujuannya agar handler yang hang lebih mudah terdeteksi.
Meski demikian, jika seluruh proses freeze, heartbeat tetap bisa berhenti. Jadi heartbeat membantu, tetapi tidak menghilangkan kebutuhan lease expiry dan reaper.
function heartbeat(jobId, token, workerId, now, leaseDuration):
updated = update jobs set
last_heartbeat_at = now,
lease_expires_at = now + leaseDuration,
updated_at = now
where id = jobId
and status = 'running'
and locked_by = workerId
and lock_token = token
return updated == 1Jika heartbeat gagal karena token tidak cocok, worker harus berhenti memproses sebisa mungkin. Itu tanda lease mungkin sudah diambil pihak lain.
3. Selesaikan job dengan compare-and-set
function completeJob(jobId, token, workerId, now):
updated = update jobs set
status = 'completed',
completed_at = now,
lease_expires_at = null,
last_heartbeat_at = now,
locked_by = null,
lock_token = null,
updated_at = now
where id = jobId
and status = 'running'
and locked_by = workerId
and lock_token = token
return updated == 1Pola yang sama dipakai untuk fail, retry scheduling, atau menyimpan hasil akhir. Ini mencegah worker lama menulis status setelah lease berpindah tangan.
Desain reaper yang aman
Reaper adalah proses terpisah yang memindai job running yang lease-nya sudah lewat dan memutuskan apakah job harus dikembalikan ke antrean, ditandai gagal, atau dibiarkan sementara. Reaper yang aman harus konservatif, dapat diaudit, dan tidak menimpa job aktif tanpa pengecekan kepemilikan.
Prinsip desain reaper
- Jangan hanya lihat
status = running; lihat jugalease_expires_atdan, bila ada, status worker. - Gunakan grace period untuk menghindari false positive saat clock skew atau lonjakan latency.
- Batasi jumlah job yang direap per siklus agar tidak membuat badai retry.
- Catat alasan reaping untuk audit dan debugging.
- Bedakan recovery otomatis dari keputusan permanen seperti fail final.
Alur keputusan reaper
- Pilih job dengan
status = runningdanlease_expires_at < now - grace_period. - Opsional: cek apakah worker pemilik masih terlihat sehat di registry atau service discovery.
- Jika worker jelas tidak sehat atau lease sudah jauh lewat, lakukan compare-and-set terhadap token saat ini.
- Pindahkan job ke
pendingdenganavailable_at = now + backoff, atau tandaifailedjika attempts melebihi batas. - Tulis event audit seperti
reaped_due_to_expired_lease.
Pseudocode reaper
function reapExpiredJobs(now, gracePeriod):
candidates = select jobs where
status = 'running'
and lease_expires_at < now - gracePeriod
limit 100
for job in candidates:
if job.attempt_count >= job.max_attempts:
updated = update jobs set
status = 'failed',
failed_at = now,
last_error = 'lease expired and max attempts reached',
locked_by = null,
lock_token = null,
lease_expires_at = null,
updated_at = now
where id = job.id
and status = 'running'
and lock_token = job.lock_token
continue
updated = update jobs set
status = 'pending',
available_at = now + computeBackoff(job.attempt_count),
locked_by = null,
lock_token = null,
lease_expires_at = null,
updated_at = now
where id = job.id
and status = 'running'
and lock_token = job.lock_tokenPerhatikan bahwa reaper juga memakai lock_token pada klausa where. Ini penting karena bisa saja job sudah diambil ulang oleh mekanisme lain tepat sebelum reaper menulis perubahan.
Mengapa perlu grace period?
Lease kedaluwarsa persis pada satu timestamp belum tentu berarti worker mati. Bisa jadi:
- heartbeat tertunda sesaat,
- database lambat,
- jam antar node tidak sinkron sempurna,
- runtime mengalami pause singkat.
Karena itu, reaper sebaiknya memakai rumus seperti:
anggap zombie jika now > lease_expires_at + grace_periodBesaran grace period bergantung pada jitter heartbeat, latency storage, dan toleransi duplicate execution. Tidak ada angka universal; yang penting adalah konsisten dengan failure mode sistem Anda.
Strategi idempotensi saat job diambil ulang
Jika sistem Anda mampu me-requeue job yang lease-nya habis, maka duplicate execution bukan kemungkinan kecil, melainkan bagian dari model eksekusi. Solusi utamanya adalah idempotensi.
1. Gunakan idempotency key untuk side effect eksternal
Jika job memanggil API pembayaran, mengirim email, membuat invoice, atau menulis ke sistem lain, sertakan idempotency_key yang stabil untuk setiap job. Pihak penerima harus mengenali permintaan duplikat dan mengembalikan hasil yang sama atau menolak eksekusi kedua secara aman.
2. Simpan hasil berdasarkan business key, bukan hanya job id
Jika job bertugas membuat record “invoice untuk order X”, pastikan ada unique constraint pada entitas hasil, misalnya berdasarkan order_id, bukan hanya mengandalkan status queue.
3. Buat operasi transisi yang monotonic
Contoh aman:
- mark as shipped hanya jika status sebelumnya belum shipped.
- insert if not exists untuk event outbox.
- upsert yang menghasilkan state akhir yang sama jika dijalankan dua kali.
Contoh berisiko:
- menambah saldo tanpa deduplication key,
- mengirim email tanpa pencatatan delivery key,
- membuat invoice baru setiap percobaan.
4. Gunakan checkpoint untuk job panjang
Jika job besar terdiri dari beberapa langkah, simpan checkpoint langkah terakhir yang berhasil. Saat job diambil ulang, worker melanjutkan dari checkpoint, bukan mengulang semua side effect dari awal.
Namun checkpoint juga perlu hati-hati. Jangan menulis checkpoint “langkah selesai” sebelum side effect langkah itu benar-benar committed.
Memilih timeout dan interval heartbeat
Tidak ada konfigurasi tunggal yang cocok untuk semua beban kerja. Yang penting adalah hubungan antar parameter.
Aturan praktis
- Interval heartbeat harus jauh lebih pendek daripada lease duration.
- Lease duration harus lebih panjang dari jitter normal, pause runtime, dan variasi latency.
- Grace period reaper harus mempertimbangkan keterlambatan heartbeat dan skew jam.
Contoh pola yang sehat secara umum:
- heartbeat tiap beberapa detik,
- lease beberapa kali lebih panjang dari interval heartbeat,
- reaper berjalan periodik dengan grace tambahan.
Jika job sering melakukan operasi blocking yang bisa melampaui lease, Anda punya beberapa opsi:
- perpanjang lease sebelum operasi panjang dimulai,
- pecah job menjadi unit yang lebih kecil,
- gunakan checkpoint agar retry lebih aman,
- naikkan lease dengan konsekuensi recovery lebih lambat.
Metrik dan alert untuk mendeteksi zombie job di produksi
Zombi job jarang terlihat dari satu metrik saja. Anda perlu menggabungkan sinyal dari queue, worker, dan storage metadata.
Metrik utama
- Jumlah job running dengan lease expired: indikator langsung kandidat zombie.
- Age of oldest running job: penting untuk mendeteksi job yang diam terlalu lama.
- Heartbeat lag:
now - last_heartbeat_atuntuk job running. - Reaped jobs count: jumlah job yang dipulihkan reaper per interval.
- Duplicate completion / dedup hit rate: tanda recovery terlalu agresif.
- Attempt count distribution: lonjakan retry bisa berarti lease terlalu pendek atau dependency eksternal bermasalah.
- Queue depth vs active workers: backlog naik saat worker macet.
- Job runtime percentile: membantu menyesuaikan lease duration.
Alert yang berguna
- Jumlah job running dengan heartbeat lag di atas ambang melonjak.
- Oldest running job melebihi runtime normal secara signifikan.
- Reaper menandai terlalu banyak job dalam waktu singkat.
- Dedup hit rate meningkat tajam, tanda duplicate execution meningkat.
- Job pending menumpuk sementara worker terlihat hidup, indikasi worker hang atau tidak bisa claim job.
Hindari alert yang hanya berbasis “queue length tinggi” tanpa konteks. Lonjakan backlog bisa normal saat traffic naik, tetapi zombie job biasanya terlihat dari kombinasi backlog, heartbeat lag, dan expired lease.
Playbook operasional saat ada indikasi zombie job
1. Konfirmasi apakah masalahnya worker mati, hang, atau broker/storage lambat
- Cek health worker process dan restart count.
- Cek CPU, memory, file descriptor, thread dump, atau goroutine dump bila tersedia.
- Cek latency database/broker dan error koneksi.
- Bandingkan timestamp heartbeat dengan log aplikasi.
2. Identifikasi ruang lingkup
- Apakah semua queue terdampak atau hanya satu queue?
- Apakah hanya job tertentu yang stuck?
- Apakah terjadi setelah deploy, perubahan konfigurasi, atau gangguan dependency eksternal?
3. Tinjau reaper sebelum menjalankan recovery manual
Jangan langsung memindahkan semua job running ke pending. Jika worker masih hidup tetapi lambat, tindakan manual bisa memicu duplikasi massal. Pastikan:
- lease benar-benar lewat lama,
- worker pemilik tidak sehat,
- job handler cukup idempotent.
4. Jika perlu recovery manual, lakukan bertahap
- Requeue batch kecil lebih dulu.
- Pantau dedup hit, error downstream, dan throughput.
- Hindari recovery global sekaligus kecuali outage memang total.
5. Setelah insiden, evaluasi parameter dan desain job
- Apakah lease terlalu pendek?
- Apakah heartbeat bergantung pada thread yang sama dengan kerja utama?
- Apakah job terlalu besar dan perlu dipecah?
- Apakah handler belum idempotent?
- Apakah reaper terlalu agresif atau terlalu lambat?
Kesalahan implementasi yang sering terjadi
Menggunakan status running tanpa expiry
Ini sumber stuck job klasik. Selalu kombinasikan status dengan lease atau visibility timeout.
Heartbeat menulis tanpa validasi token
Jika update heartbeat hanya berdasarkan job_id, worker lama bisa memperpanjang lease yang sudah berpindah ke worker baru.
Menganggap “exactly once” tanpa dukungan end-to-end
Di praktik nyata, queue sering hanya memberi jaminan at-least-once. Jika side effect tidak idempotent, duplicate execution akan muncul cepat atau lambat.
Lease terlalu pendek dibanding perilaku runtime
GC pause, I/O lambat, atau throttling CPU bisa membuat heartbeat telat. Akibatnya reaper aktif padahal worker masih sehat.
Lease terlalu panjang untuk job yang sering crash
Ini mengurangi duplicate execution, tetapi memperlambat pemulihan. Backlog bisa menumpuk lama saat worker mati.
Pola implementasi yang bisa diterapkan lintas stack
Walau detail teknis berbeda antara Redis, database SQL, broker pesan, atau queue managed service, pola umumnya tetap sama:
- Klaim job dengan kepemilikan terbatas waktu melalui lease atau visibility timeout.
- Perbarui liveness secara periodik lewat heartbeat.
- Lindungi semua update dengan token kepemilikan agar hanya pemilik saat ini yang boleh mengubah status.
- Jalankan reaper yang konservatif untuk memulihkan job yang benar-benar terlantar.
- Asumsikan duplicate execution bisa terjadi dan desain handler agar idempotent.
- Ukur heartbeat lag, expired lease, retry, dan dedup agar zombie job terlihat sebelum menjadi insiden besar.
Penutup
Mencegah job zombie bukan soal menambahkan timeout semata, tetapi menyusun kontrak yang jelas antara worker, queue, dan storage metadata. Lease atau visibility timeout memberi batas kepemilikan, heartbeat memberi sinyal liveness, dan reaper memulihkan job yang benar-benar terlantar. Namun semua itu tetap harus ditopang oleh idempotensi, karena duplicate execution adalah konsekuensi realistis dari sistem terdistribusi.
Jika Anda ingin desain yang aman, mulailah dari model sederhana: metadata job minimal, token kepemilikan, heartbeat periodik, reaper dengan grace period, dan handler yang tahan diambil ulang. Dari sana, observabilitas dan tuning timeout akan jauh lebih mudah dilakukan tanpa menciptakan zombie baru di produksi.
Komentar
0 komentar
Masuk ke akun kamu untuk ikut berkomentar.
Belum ada komentar
Jadilah yang pertama ikut berdiskusi!